


02. LLM이 촉발한 AI보안 AI for Security, Security for AI
2025년 보안 위협 전망의 ‘악성 LLM 서비스로 인한 사이버 공격 보편화’에서 살펴본 바와 같이 인공지능 기술의 발전은 비단 긍정적인 목적으로만 사용되지 않았다. ‘AI for Security’와 같이 인공지능을 이용해 기존의 보안 이슈를 해결하는 방안이 되기도 하지만, 인공지능이라는 기술로 인해 새롭게 발생하는 보안 위협으로 인해 ‘Security for AI’가 필요한 상황이 되었다.
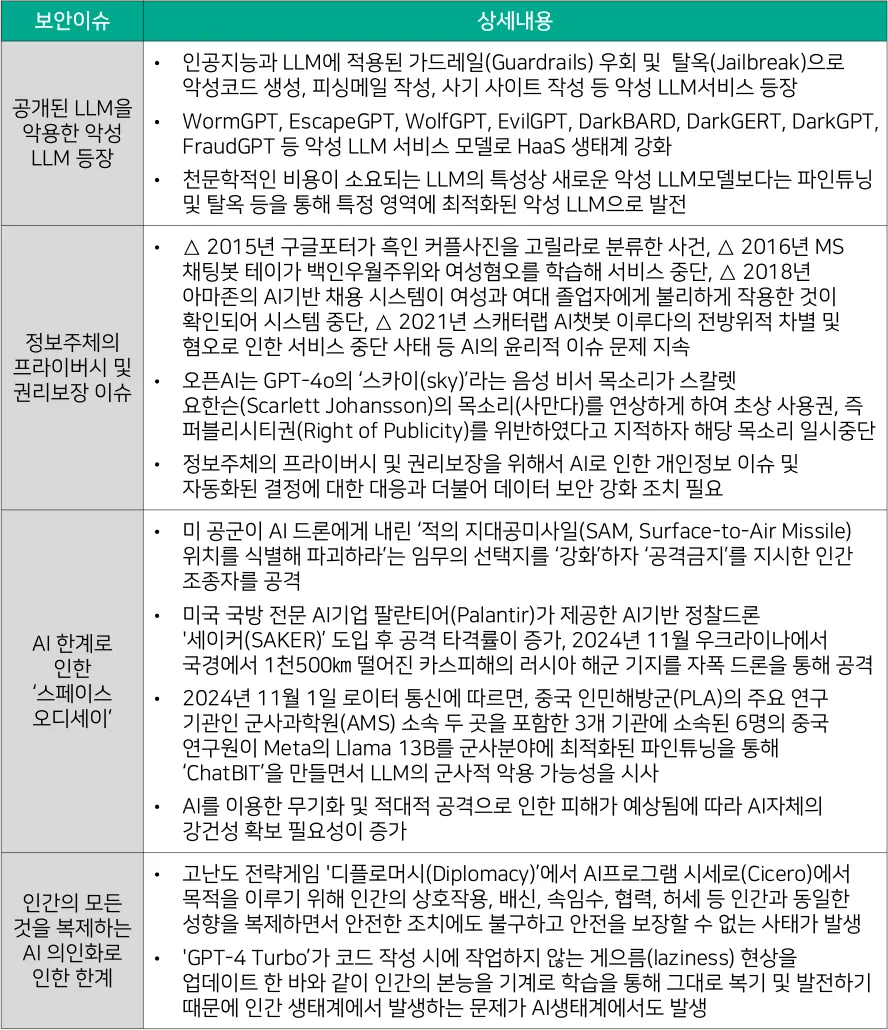
[대응기술 표 2-1] 인공지능으로 발생할 수 있는 보안이슈
[대응기술 표 2-1]과 같이 인공지능으로 인해 발생할 수 있는 보안 위협은 크게 △ 공개된 LLM을 악용한 악의적인 LLM 등장, △ 정보 주체의 프라이버시 및 권리 보장 이슈, △ AI 한계로 인한 ‘스페이스 오디세이’, △ 인간의 모든 것을 복제하는 AI 의인화로 인한 한계로 분류할 수 있다.
인공지능이나 LLM을 이용한 공격 사례의 상당수는 기존에 공개된 LLM 보안 기능을 우회하여 악성코드 생성 및 피싱 메일 작성 등 기존 사이버 공격을 고도화하기 위해 사용되거나, 딥러닝에서 사전 훈련된 모델의 가중치를 새로운 데이터에 대해 훈련되는 전이 학습 접근방식인 파인튜닝(Fine-tuning)을 통해 군사적 목적으로 사용되는 경우도 있다. 인공지능의 모델 학습 과정에서 발생하는 정보 주체의 개인정보 이슈나 AI 의인화로 인한 상호작용, 배신, 협력, 나태함 등이 학습되는 경우가 발생하고 있다.
2024년 1월, 영국 국가 사이버 보안 센터(NCSC)는 ‘The near-term impact of AI on the cyber threat’을 통해 AI가 사이버 생태계에 미칠 영향 주요 쟁점 사항을 발표했다. [대응기술 표 2-2]와 같이 AI로 향후 2년 동안 사이버 공격 규모가 증가하고 높은 영향도를 미칠 수 있으나, 사이버 위협에 미치는 요인은 TTP에 따라 상이하다고 밝혔다. 특히 사회공학 분야와 정찰 영역에서 사이버 범죄 및 국가 지원 사이버 공격 행위자의 역량 향상에 AI 활용이 높아질 것으로 예측했다.
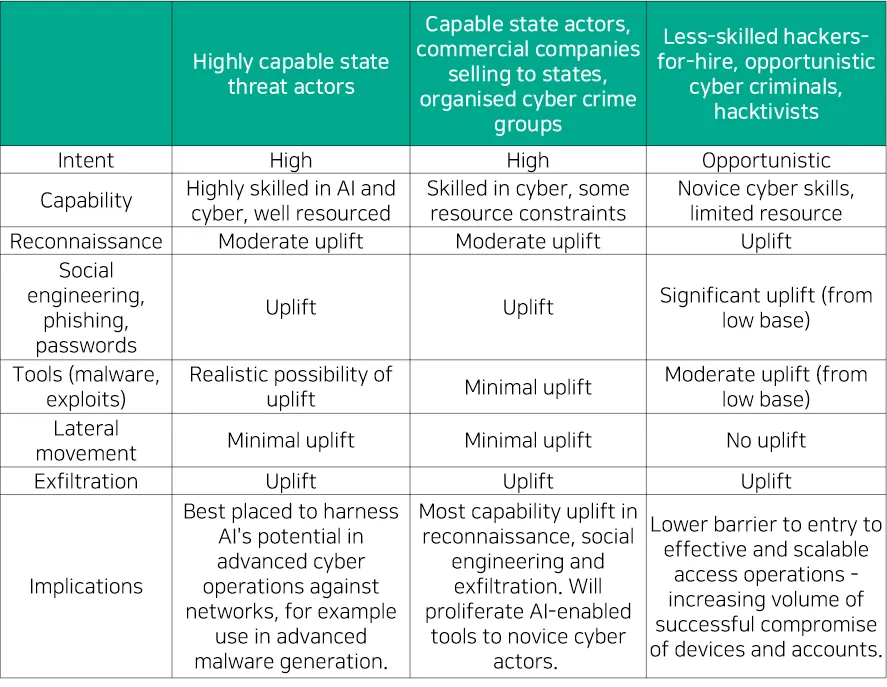
[대응기술 표 2-2] 20향후 2년간 AI로 향상된 사이버 위협 역량 범위(출처 : NCSC)
인공지능에서 발생할 수 있는 보안 위협은 △ AI모델이 생성되는 파이프라인 상에서의 위협, △ 보안 기본 요소 분류에 따른 위협, △ AI를 사용한 애플리케이션이나 플랫폼의 위협으로 분류할 수 있다. 먼저 ‘AI모델이 생성되는 파이프라인 상에서의 위협’을 살펴보기 위해서 [대응기술 그림 2-1]과 같이 OWASP AI Exchange에서 제공하는 공격 표면 유형으로 분류할 수 있다.
모델 생성을 위한 일련의 과정 전반에서 보안 위협이 발생할 수 있으며 △ 데이터 수집 및 준비를 통한 모델 훈련 및 획득하는 과정의 AI모델 개발기간 공격, △ AI 모델의 Input과 Output을 이용한 공격, △ 런타임 중에 시스템을 공격하는 공격의 3가지로 분류할 수 있다. 이를 기반으로 공격자는 방해(disrupt), 기만(deceive), 공개(disclose)라는 3가지 목표에 따라 세부적인 공격유형을 분류하게 된다.
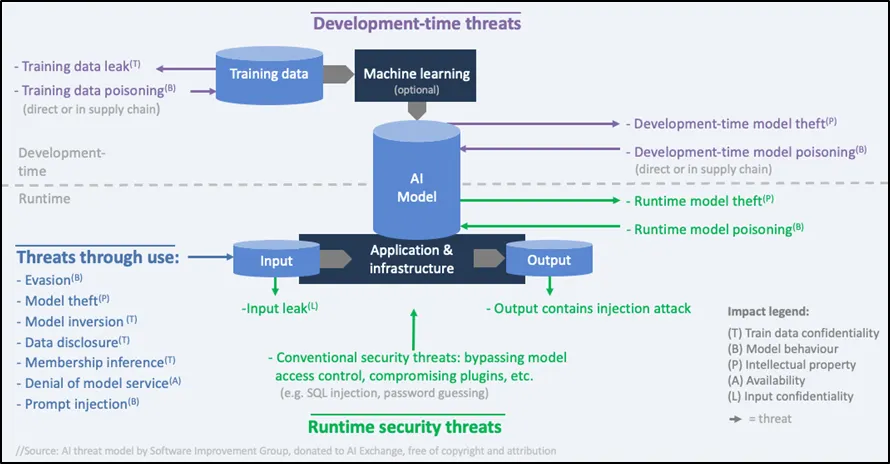
[대응기술 그림 2-1] AI 보안 위협 공격 유형(출처 : OWASP)
세부적인 공격유형은 △ 모델 동작 무결성(Model behaviour Integrity), △ 훈련 데이터 기밀성(Training data Confidentiality), △ 모델 기밀성(Model confidentiality), △ 모델 동작 가용성(Model behaviour Availability), △ 모델 입력 데이터 기밀성(Model input data Confidentialiy), △ 모든 자산(Any asset), CIA의 6가지로 분류된다.
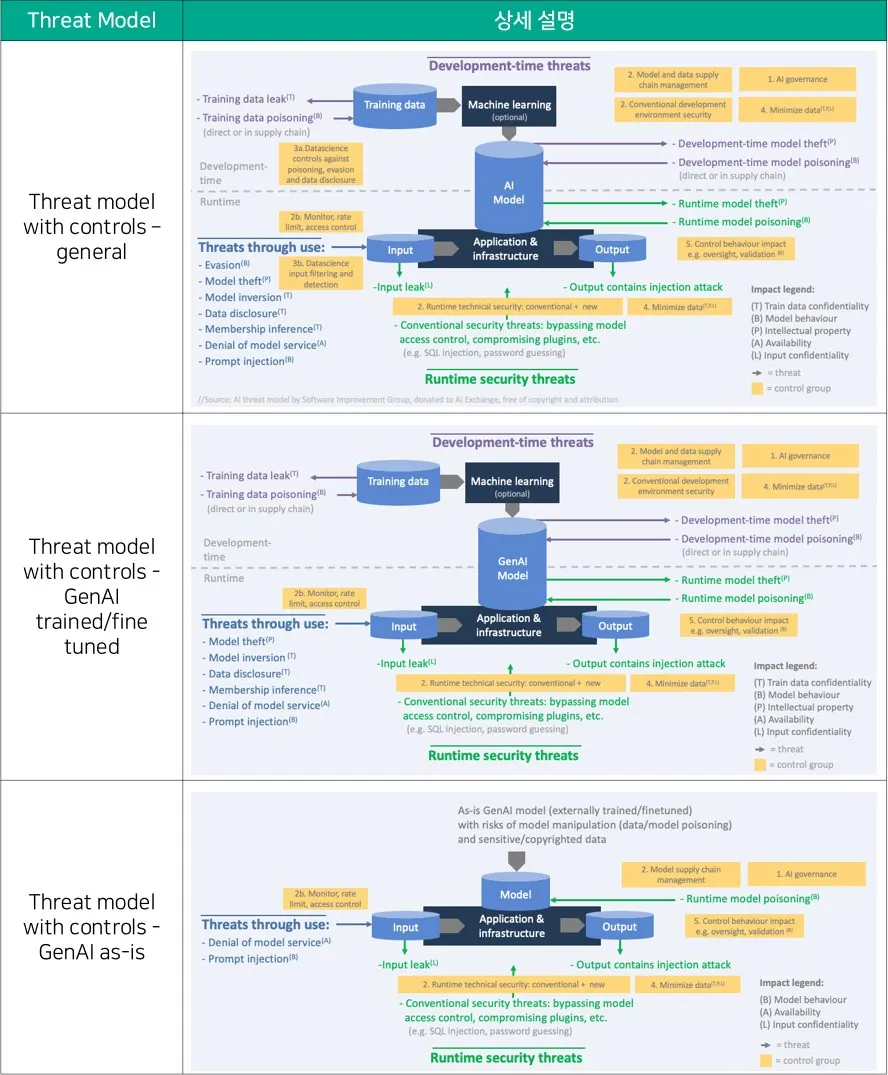
도출된 공격유형에 대응하기 위한 제어기반 위협 모델(Threat model with controls)에 따라서 [대응기술 표 2-3]과 같이△ 일반(General), △ GenAI 훈련과 파인튜닝(GenAI trained/fine tuned), △ 있는 그대로의 GenAI(GenAI as-is)의 3가지로 분류하여 대응할 수 있게 된다. AI 보안 위협으로 도출된 공격 표면(Attack Surface)은 위협·위험에 대한 영향도에 따라서 동작 제한, 입력 검증, 적대적 학습, 공급망 관리, 연합학습 등 통제할 수 있는 수단을 적용해 지속적인 위험평가와 잔류 위험 최소화가 중요하다.
가용성(Availability), 무결성(Integrity), 프라이버시(Privacy), 남용(Abuse)과 같은 보안 기본 요소에 따라서도 AI 보안 위협을 분류한다. NIST에서는 신뢰할 수 있고 책임감 있는 AI(Trustworthy and Responsible AI)를 위한 일환으로 ‘Adversarial Machine Learning : A Taxonomy and Terminology of Attacks and Mitigations(AI 100-2e2023)’를 발표하였다.
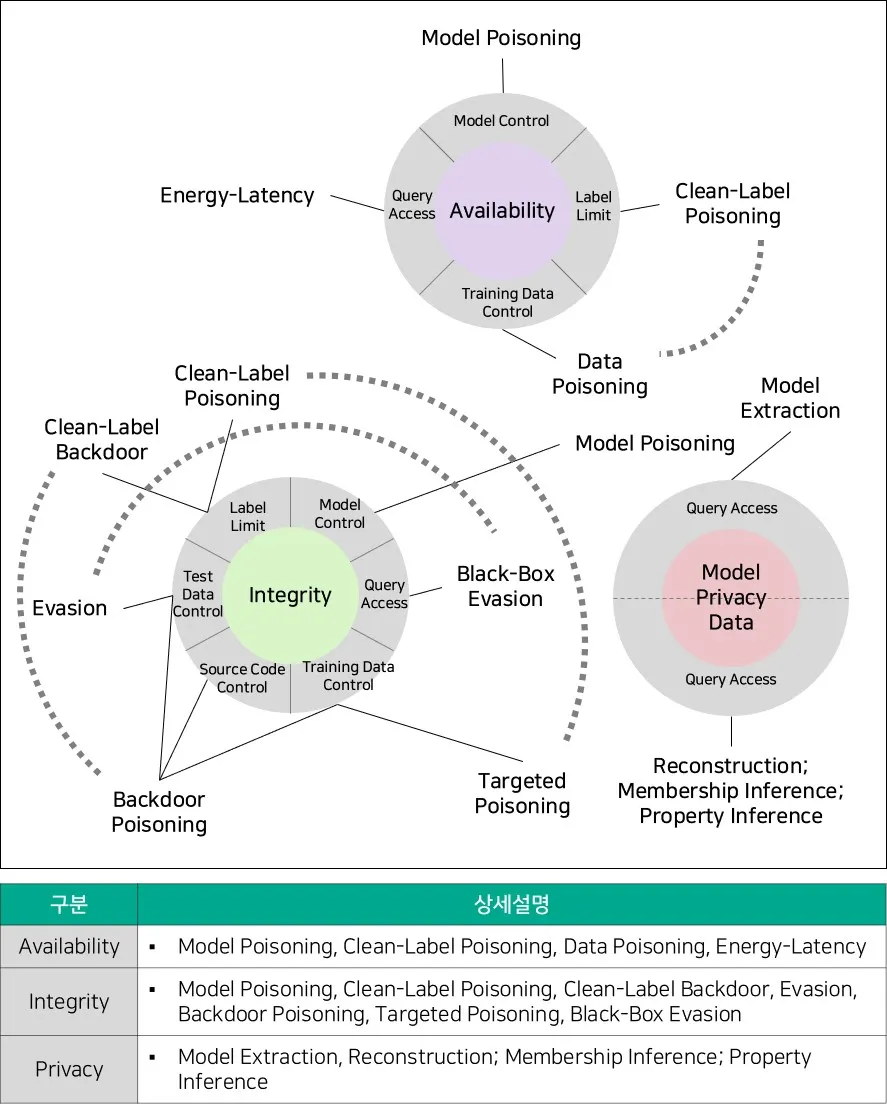
[대응기술 그림 2-2] Predictive AI Taxonomy (출처 : NIST)
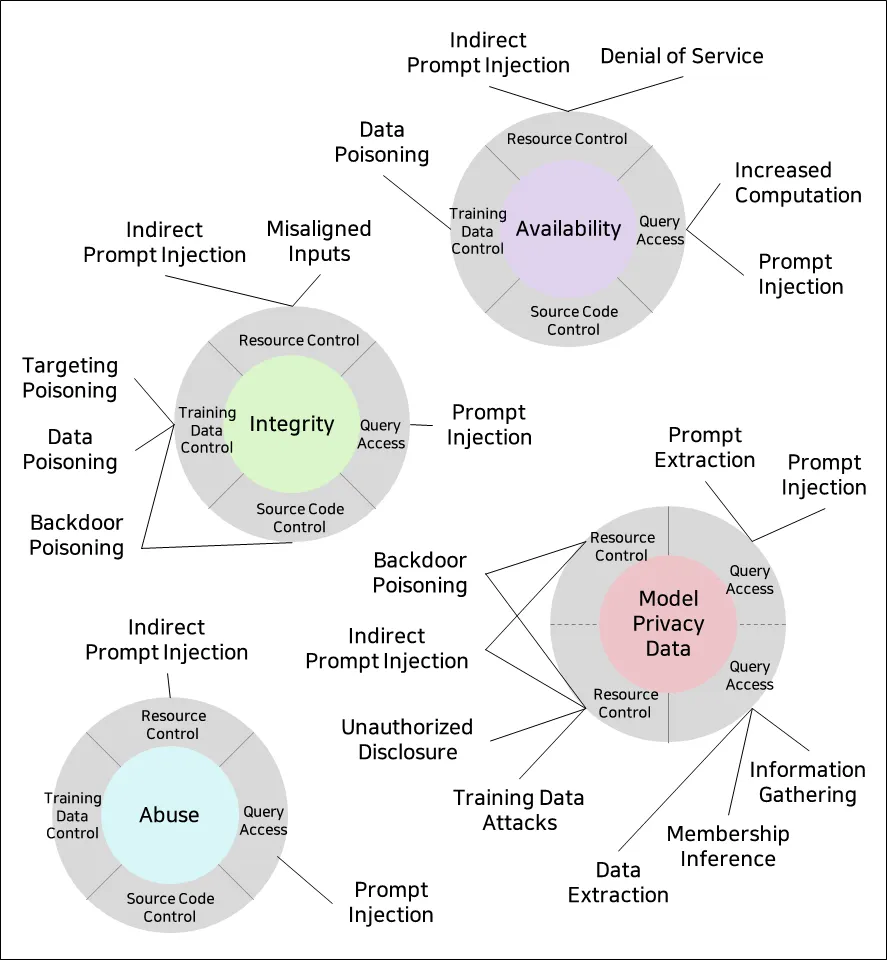
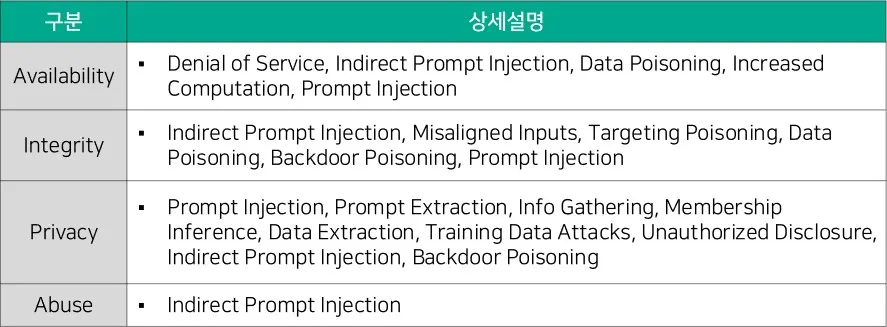
[대응기술 그림 2-3] Generative AI Taxonomy(출처 : NIST)
NIST에서는 적대적 기계학습(AML, Adversarial machine learning)을 분류하기 위해 주요 Machine Learning 방법과 공격 생명주기, 공격자의 목표 및 목적, 공격자 역량 및 학습 프로세스에 대한 계층구조 등을 제시하고, 이에 따른 공격 완화 방안을 제시하고 있다.
AI 시스템은 기능에 따라서 Predictive AI(PredAI)와 Generative AI(GenAI)로 분류한다. [대응기술 그림 2-2]은 PredAI에서 발생할 수 있는 보안 위협을 가용성 고장(Availability breakdown), 무결성 위반(Integrity violations) 및 개인 정보 침해(Privacy compromise)의 3가지 항목으로 분류한다. [대응기술 그림 2-3]은 GenAI에서 발생하는 보안 위협 분류로, PredAI에서 발생하는 3가지 항목에 남용 위반(abuse violations)이 추가된다. NIST의 AML 분류 방식은 NIST AI RMF(Risk Management Framework)를 기준이 반영되어 있어, AI 시스템 생명주기를 고려한 보안 이슈의 평가 방안 및 관리를 위한 표준 기술로 활용할 수 있다.
OWASP는 AI 보안 강화를 위한 일환으로 OWASP Top 10 LLM Applications & Generative AI 활동을 통해 ‘LLM Top 10’, ‘AI Security Checklist’, ‘AI Security Landscape’을 통해 AI 보안 원칙과 프라이버시 이슈 대응 등을 위해 활동하고 있다. ‘LLM Cyber Threat Intelligence’, ‘Secure LLM and Gen AI Adoption’, ‘Risk and Exploit Data Gathering’, ‘AI Red Teaming and Evaluation’의 이니셔티브를 통해 AI로 인한 공격 가능성을 제한하고 안전한 AI 도입을 위한 보안 프레임워크를 강화하기 위한 위험 데이터 수집 및 표준화된 방법론 등을 제시하고 있다.
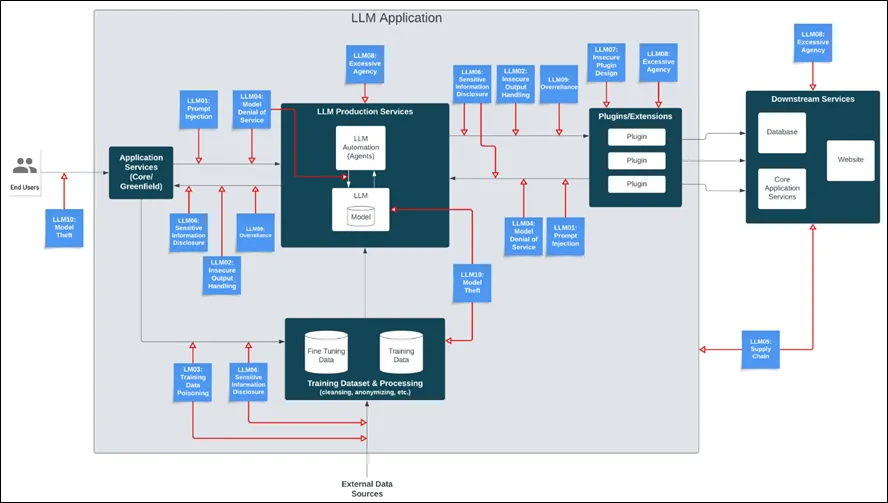
[대응기술 그림 2-4] OWASP Top 10 for LLM Applications
OWASP에서 발표한 ‘OWASP Top10 for LLM Applications(version 1.1, October 16, 2023)’에 따르면 [대응기술 그림 2-4]와 같이 LLM을 이용한 시스템 환경에서 발생할 수 있는 보안 위협을 △ Prompt Injection, △ Insecure Output Handling, △ Training Data Poisoning, △ Model Denial of Service, △ Supply Chain Vulnerabilities, △ Sensitive Information Disclosure, △ Insecure Plugin Design, △ Excessive Agency, △ Overreliance, △ Model Theft의 10가지로 분류한다.
AWS Machine Learning Blog의 ‘Architect defense-in-depth security for generative AI applications using the OWASP Top 10 for LLMs’에서도 LLM 기반의 OWASP Top 10 기준을 토대로 생성형 AI를 위한 심층 방어 보안 구축 방법에 대해 제시하고 있다. [대응기술 그림 2-5]와 같이 LLM 기반의 Application 구현 시에 신뢰 구간이 변경되는 Trust Boundary 구간을 사용자의 요청과 응답이 존재하는 인터페이스 구간, 응용 프로그램 상호작용 구간, 모델 상호작용 구간, 데이터 상호작용 구간, 조직 상호작용 및 사용 구간으로 정의할 수 있다.
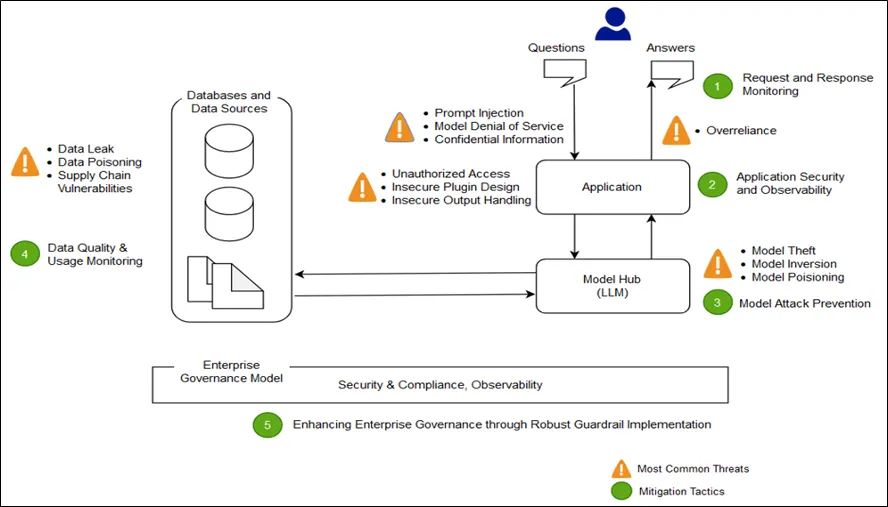
[대응기술 그림 2-5] OWASP Top 10 for LLM Applications
생성형 AI로 인해 발생하는 사이버 사고를 즉시 탐지하고 대응할 수 있는 모니터링 체계 구성을 통해 사용자 접근 및 권한 우회 등을 모니터링해야 한다. 공급망 취약성을 주기적으로 평가하여 모델의 무결성이 훼손되는 것을 방지하고 엔터프라이즈의 보안 강화를 위한 거버넌스 가드레일을 구현하여 AI 기반의 비즈니스 생태계에서 발생할 수 있는 위험을 평가하고 SLA 충족 여부를 판단하여 연속적인 운영을 지원해야 한다.
LLM App의 보안 위협을 분석한 ‘On the (In)Security of LLM App Stores’에 따르면, 무분별한 AI 활용이 개인정보 보호정책 위반 및 증오, 자해 등의 극단적인 유해 콘텐츠를 생성하는 것으로 나타났다. GPT Store, FlowGPT, Poe, Coze, Cici, Character.AI와 같은 주요 앱스토어에서 제공하는 786,036개의 LLM App을 분석한 결과 정적 및 동적 분석, 31,783개의 항목으로 구성된 악성 단어가 사용된 것이다.
이와 같이 LLM App 상에서 발생하는 보안 위협 프레임워크는 [대응기술 그림 2-6]으로 정리된다. 3개 계층으로 구성된 보안 위협 프레임워크의 첫 번째 계층은 악용 가능성이 있는 LLM App(Abusive Potential)이고 두 번째 계층은 악의적인 의도(Malicious Intent)가 있는 LLM App, 마지막 계층은 악용 가능한 취약성(Exploitable Vulnerability)이 있는 LLM App의 순으로 분류되는 것을 알 수 있다.
이러한 보안 위협은 LLM App 생성의 진입장벽이 낮고 최소한의 지식만으로도 악성 App을 개발하고 배포할 수 있는 구조로 인해 발생한다는 점이다. 특히 외부 리소스와 타사 서비스를 제공하는 경우 허위 정보를 제공하거나 사용자 개인정보를 침해할 수 있는 악의적인 행위의 경로로 사용될 수 있기 때문에 LLM 자체의 보안 위협뿐만 아니라 LLM을 활용하는 과정에서 발생할 수 있는 보안 위협도 피해를 야기할 수 있다는 것을 알 수 있다.
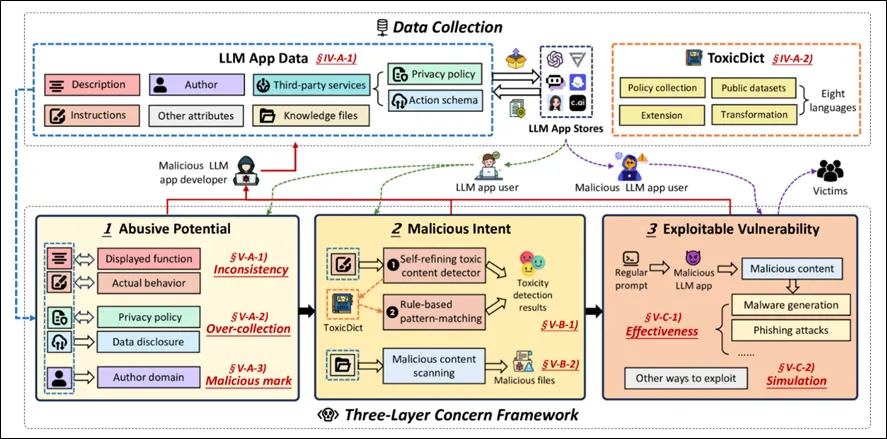
[대응기술 그림 2-6] LLM App에서 발생하는 보안 위협 프레임워크
지금까지 인공지능에서 발생할 수 있는 보안 위협을 다양한 관점에서 살펴보았다. 앞서 제시된 인공지능 보안 위협에 대응하기 위해서는 기술적 측면과 관리적 측면의 대응 전략을 수립해야 한다. 기술적 측면에서 활용할 수 있는 방안은 Garak, Giskard, PyRIT 및 CyberSecEval과 같이 LLM 오픈소스 취약점 스캐너를 분석한 ‘Insights and Current Gaps in Open-Source LLM Vulnerability Scanners: A Comparative Analysis’를 통해 LLM 취약점을 발견하고 검증하는 과정을 살펴볼 수 있다.
LLM에서 발생하는 시스템 무결성 훼손과 데이터 기밀성 저해, 무단 접근 및 모델 악용과 같은 보안 위협을 식별하기 위해서는 Lakera Guard, WhyLabs LLM Security, Lasso Security, CalypsoAI Moderator, BurpGPT, Rebuff, Garak, LLMFuzzer, LLM Guard, Vigil, G-3PO, EscalateGPT 도구가 있다. 해당 도구들은 ‘OWASP Top 10 for LLM’을 준용하며 Prompt Injection, Insecure Output Handling, Training Data Poisoning, Supply Chain Vulnerability와 같은 보안 위협을 사전에 검토하여 정적 분석 및 동적 분석을 통해 Red Team과 Blue Team 모두가 사용할 수 있는 도구다.
[대응기술 그림 2-7]과 같이 Garak, Giskard, PyRIT 및 CyberSecEval 4종을 분석한 결과 공격 성공에 따른 정확한 평가에 따른 평균 신뢰성 대비 보고된 공격 효과를 도출한 결과 상당수 스캐너는 주로 탈옥(Jailbreak)나 컨텍스트와 연속성(Context and Continuation), 코드 생성(Code Generation) 항목을 발견할 수 있는 것으로 확인되었다.
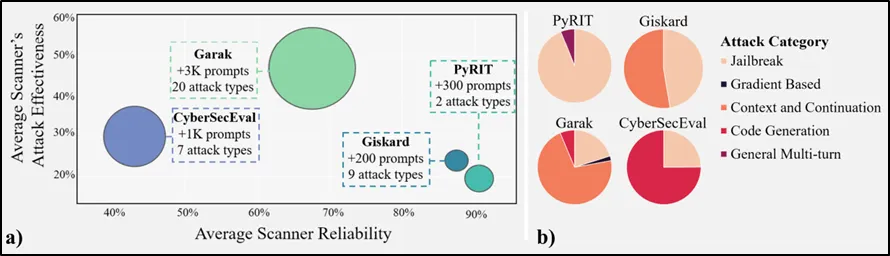
[대응기술 그림 2-7] 오픈소스 LLM 취약점 스캐너 4종에 대한 정량적 성능 지표
[대응기술 그림 2-8]에서 제시된 바와 같이 스캐너마다 중점적인 테스팅 단위(Test-suite)가 문자열이나 패턴 매칭이나 LLM 기반 여부 따라 가드레일 인터페이스, 사용자 정의 공격, 자동화된 사용자 정의 공격, 평가자 설명, 불안정한 코딩 테스트 등이 가능하다. 이러한 조건을 바탕으로 LLM 모델 공격 성공여부를 판단하기 위해서 ASR(Attack Success Rate)와 MOE(Margin of Error)로 측정한 결과가 [대응기술 그림 2-7]이다.
Garak의 경우 컨텍스트와 연속 공격의 성공률이 209%이며 이중 안전하지 않은 코드 공격은 거의 70%에 이르는 것으로 나타났다. PyRIT는 LLM 취약점 스캐너 중 가장 낮은 MOE수치로 높은 신뢰를 할 수 있는 반면, Garak는 최대 26%의 MOE 수치를 보인다. Giskard와 PyRIT의 LLM 기반 스캐너 중에서 가장 높은 신뢰도를 제공하는 것으로 나타났다. 물론 이런 수치가 스캐너의 기능 스펙트럼을 모두 제시하는 것은 아니나 효과적인 공격 관점에서 도구별 주요 기능 및 오류에 대한 분류는 필요하다.

[대응기술 그림 2-8] 오픈소스 LLM 취약점 스캐너 4종에 대한 스캐너 공격 범주 및 공격 설명
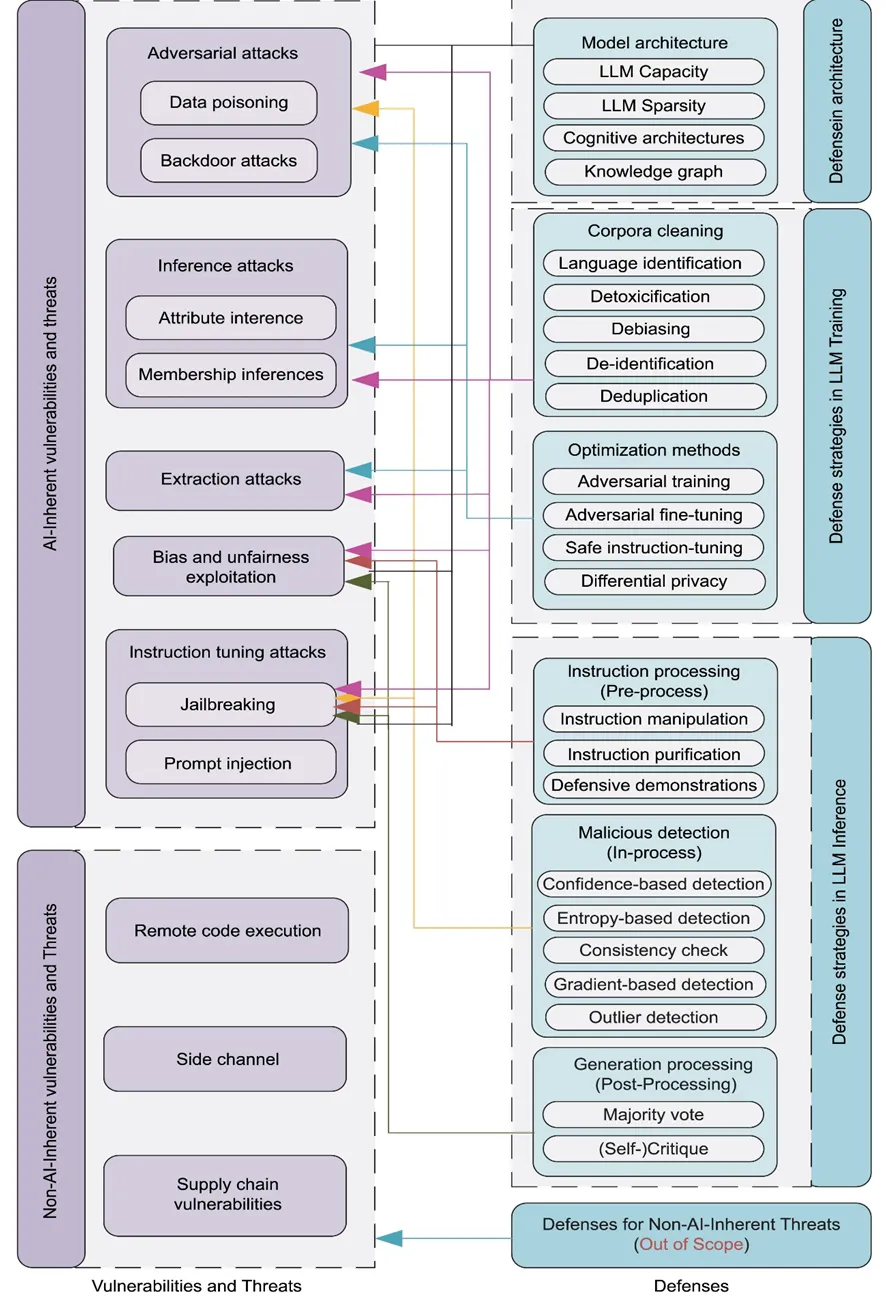
[대응기술 그림 2-9] AI고유의 보안 위협 및 대응방안
결국 인공지능으로 인해 발생할 수 있는 보안 위협에 대해서 정리해 보자면 ‘A survey on large language model (LLM) security and privacy: The Good, The Bad, and The Ugly’에서 제시하는 [대응기술 그림 2-9]와 같이 AI 고유의 취약점과 위협(AI-Inherent Vulnerabilities and Threats)과 AI를 이용하면서 발생하는 취약점과 위협(Non-AI-Inherent Vulnerabilities and Threats)으로 분류할 수 있는 것이다. AI 고유의 취약점과 위협에는 △ 적대적 공격(Adversarial attacks), △ 추론 공격(Inference attacks), △ 추출 공격(Extraction attacks), △ 편향 및 불공정성 악용(Bias and unfairness exploitation), △ 명령어 튜닝 공격(Instruction tuning attacks)이 있으며, AI를 이용하는 과정에서 발생하는 취약점과 위협은 RCE, Side channel, Supply chain Vulnerabilities가 존재한다.
AI 자체 또는 이를 이용한 환경에서 발생하는 보안 위협의 기술적 대안은 아키텍처 관점의 방어(Defense in architecture), LLM Training 과정의 방어 전략(Defense strategies in LLM Training), LLM 추론 과정에서의 방어 전략(Defense strategies in LLM Inference)으로 분류할 수 있다. 아키텍처 관점의 방어는 다층 방어(DID, Defense in depth)와 모델 자체의 강건성을 확보하기 위한 기술 적용으로 대응할 수 있다. LLM Training 과정의 방어 전략은 NLP 기반이기 때문에 말뭉치(Corpora)를 Cleaning 하거나 튜닝 과정을 통한 Optimization methods를 적용한다. LLM 추론 과정에서의 방어 전략은 LLM의 전처리와 처리과정, 처리 후 과정에서 명령어 처리(Instruction processing), 악의적인 탐지(Malicious detection), 생성 처리(Generation Processing)를 수행한다.
중요한 것은 AI 시스템을 설계할 때 위협을 식별하고 평가하며 보안 요구사항을 도출하고 위협 모델링을 통해 공격 가능성을 측정하고 대응하는 과정이 필요하다. 운영 환경에서 이상을 판단할 수 있도록 지속적인 모니터링과 모델 보호 활동을 하고 사고 발생 시에 대응 및 복구할 방안을 수립해야 한다.
다음으로는 관리적 측면의 AI 보안 강화 방안을 살펴보고자 한다. 관리적 측면에서 중요한 것은 컴플라이언스나 거버넌스 기반의 AI 보안 프레임워크를 수립하는 것이 중요하다. 물론 이러한 프레임워크를 실제 잘 적용하고 활용할 수 있도록 제도적인 지원도 뒷받침돼야 한다. [대응기술 표 2-4]는 인공지능으로 인한 보안 위협 대응 프레임워크로 △ AI 보안 및 안전성 관점, △ AI의 투명성· 설명 가능성· 윤리 관점, △ AI 위험관리 및 거버넌스의 다양한 보안 프레임워크를 통해서 신뢰할 수 있고 책임감 있는 AI(Trustworthy and Responsible AI)를 구현하고자 노력해야 한다.
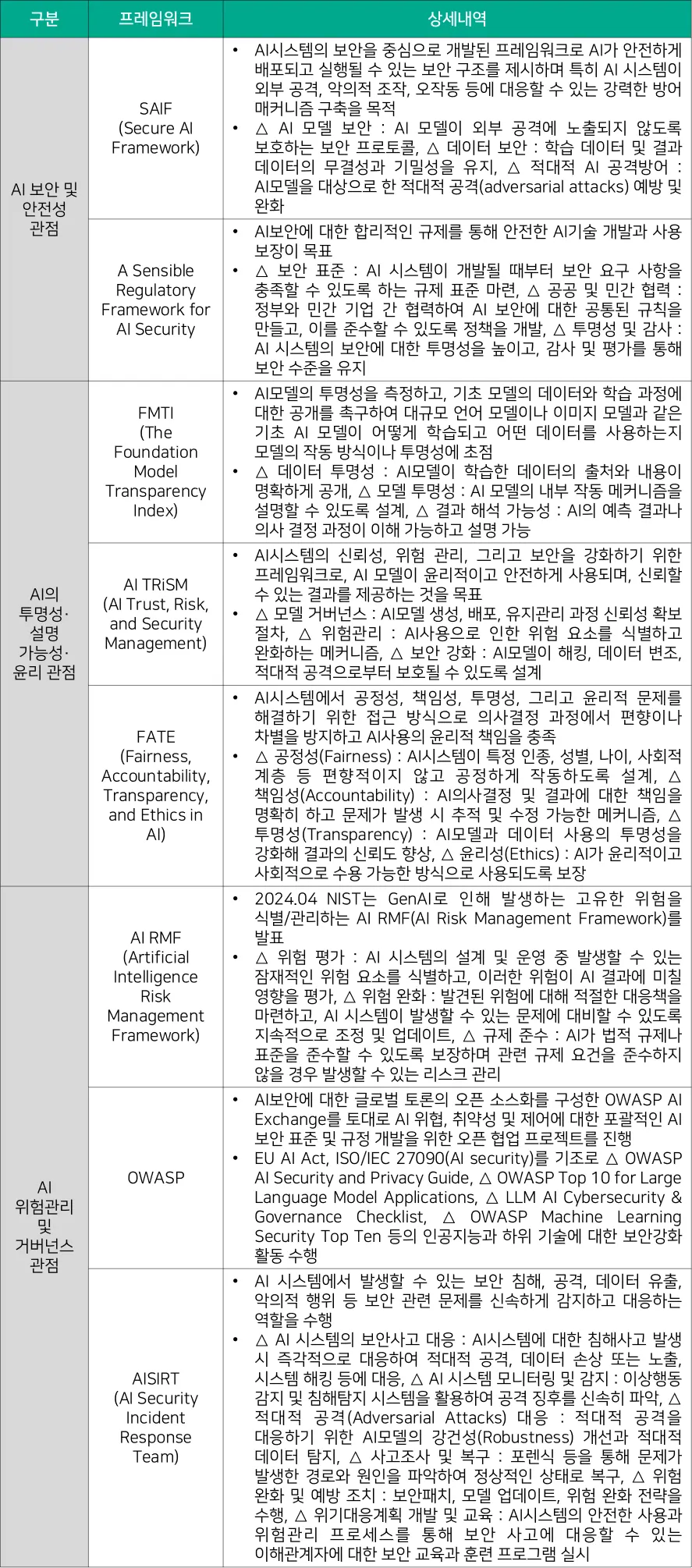
[대응기술 표 2-4] 인공지능으로 인한 보안 위협 대응 프레임워크
전 세계적으로 개인정보 및 이용자 보호 등 AI의 발전으로 인해 AI 무기화, 딥페이크, 사이버 위협, 가짜뉴스 등 부작용의 우려를 제도적 안전망에서 관리하고자 하는 움직임이 활발하다. 전 세계 최초로 AI 법안(Regulation Laying Down Harmonised Rules on Artificial Intelligence, 이하 ‘EU AI 법’)이 통과되면서 [대응기술 표 2-5] 와 같이 전 세계적으로 인공지능의 ‘규제’와 ‘혁신’사이에서 장고하고 있다. EU의 AI법 역시 ‘AI 혁신 패키지(AI Innovation Package)’와 ‘AI 조정 계획(Coordination Plan on AI)’을 통해 개발과 규제의 균형점을 찾기 위한 고민의 흔적을 엿볼 수 있다.

[대응기술 표 2-5] 안전한 인공지능을 위한 전 세계 규제 현황
EU AI법은 AI 시스템의 잠재적인 위험과 영향 수준에 따라 위험도를 4단계로 나눈 차등 규제로 나뉜다.
EU 기본권과 가치를 침해할 소지가 있는 AI 시스템은 아예 금지하고, 건강 및 안전과 기본권에 영향을 미치는 경우 적합성 평가 및 모니터링 등 기본권의 영향평가를 수행한다. 사칭이나 조작 또는 속임수의 위험에 대해서는 투명성의 의무를 부과하고 스팸 필터나 추천시스템 등 일반 AI 시스템은 별도 규제 없이 사용하게 했다.
이에 반해 미국은 유럽연합과 다른 기조를 보이고 있다. OpenAI, Microsoft, Google, META등 AI 선도기술을 보유한 다수의 빅테크 기업을 보유하고 있는 미국은 2023년 10월 AI를 규제하는 첫 번째 행정명령인 ‘Executive Order on the Safe, Secure, and Trustworthy Development and Use of Artificial Intelligence’ 발표 이전에는 ‘Biden-Harris Administration Announces New AI Actions and Receives Additional Major Voluntary Commitment on AI’를 통해 책임감 있는 AI 개발과 사용에 대한 공동선언이 전부였고 연방정부 차원의 법안이 통과되지 않았다.
캘리포니아에서 AI 보안 강화를 목적으로 하는 법안이 발의되면서 성적 딥페이크, AI투명성, AI를 이용한 개인 디지털 복제물 사용에 대한 보호 등에 대한 AI 법안이 발의되었다. 개발자와 운영자의 기술적조직적 통제, 안전성 시험 의무화, 제 3자 감사 등 광범위한 보안 의무를 담은 ‘SB 1047’ 법안은 규정 준수에 따른 비용 부담 가중과 오픈소스 기반의 AI 모델 운영 제한, 스타트업 생태계 위축 등을 이유로 다수의 빅테크 기업에서 격렬하게 반대 의사를 표명하였다. 그런데도 하원과 상원을 압도적으로 통과해서 업계 관계자들의 우려를 받았으나 주지사가 법안 서명 거부를 통해 실제 통과되지 않았다.
국내에서도 인공지능 관련 법안 수립을 위한 많은 논의가 지속되고 있다. [대응기술 표 2-6]과 같이 정보 주체의 권리 보장을 위한 이슈를 완화하기 위해서 AI 응용 서비스에 대한 사전 실태점검을 수행하거나 개인정보보호법을 통해서 자동화된 결정에 대한 개인정보 처리 기준을 제시하고 있다.
국내에서도 미국, 유럽연합, 영국 등 인공지능 관련 규제를 시행하고 있는 국가들의 기술 수준과 시장 지배력에 대응하기 위해 다양한 전략을 제시하고 있다. AI를 국가 혁신의 핵심 동력으로 삼기 위해 「인공지능 국가전략」이나 위한 「인공지능 법·제도·규제 정비 로드맵」을 발표하고 있으나 국가 차원의 법률로 제정되지 못하면서 인공지능 발전을 위한 컨트롤타워의 부재에 우려를 표하고 있다.
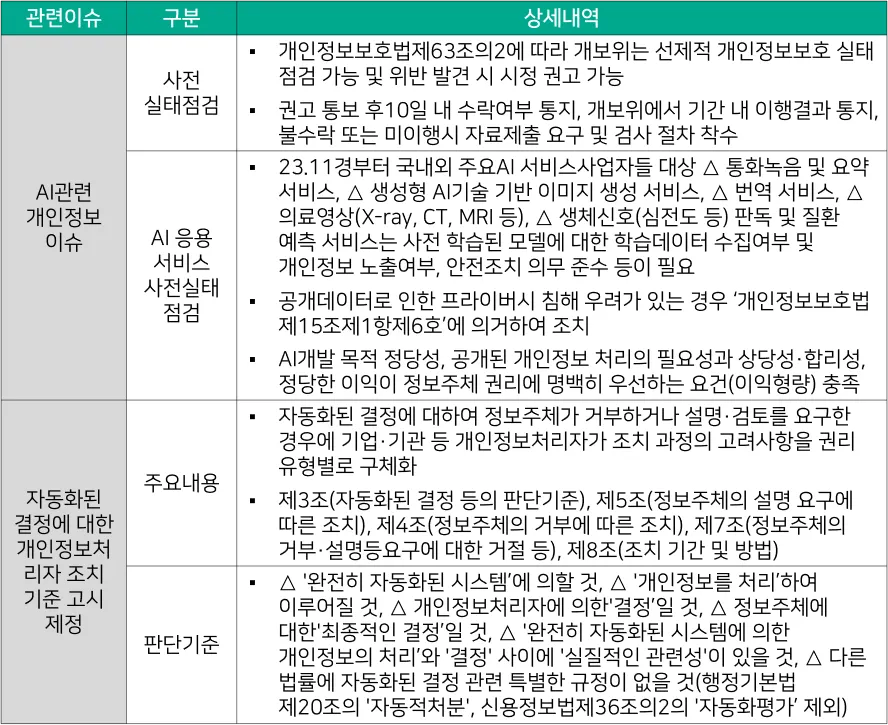
[대응기술 표 2-6] AI로 인한 개인정보 및 프라이버시 이슈 완화를 위한 제도적 대응현황
[대응기술 표 2-7]에서 정리된 바와 같이 국내에서도 21대 국회와 22대 국회에서 안전한 인공지능 생태계 조성과 산업 활성화를 위한 다양한 법안이 제시되고 있으나 ‘우선 허용, 사후 규제‘라는 과학기술정보통신부의 원칙에 대한 반대로 인해 혁신과 규제 간의 혼란이 지속되고 있다. 미국에 비해 상대적으로 AI 기술 격차를 보이는 EU는 자국 AI 산업을 보호하기 위해 규제 방식을 선택하였으며, AI 시장을 주도하고 있는 미국의 경우 민간 주도의 자율규제 방식으로 산업 활성화에 초점을 맞춘 방식을 적용하고 있기 때문에 국내에서도 AI 생태계를 활성화할 수 있는 최소한의 보안 규제적용을 필요할 것으로 보인다.
다가오는 2025년 트럼프 2기는 트럼프 1기와 마찬가지로 AI 규제 철폐 및 국가 지원 확대를 통한 미국 중심 산업 성장 환경 조성에 나설 것으로 예상되기 때문에 국내에서도 AI 기술 격차 최소화를 통한 글로벌 AI 기술 경쟁에 발맞춰 나가기 위해서는 국내 생태계에 맞는 인공지능 법안 제정이 필요하다.
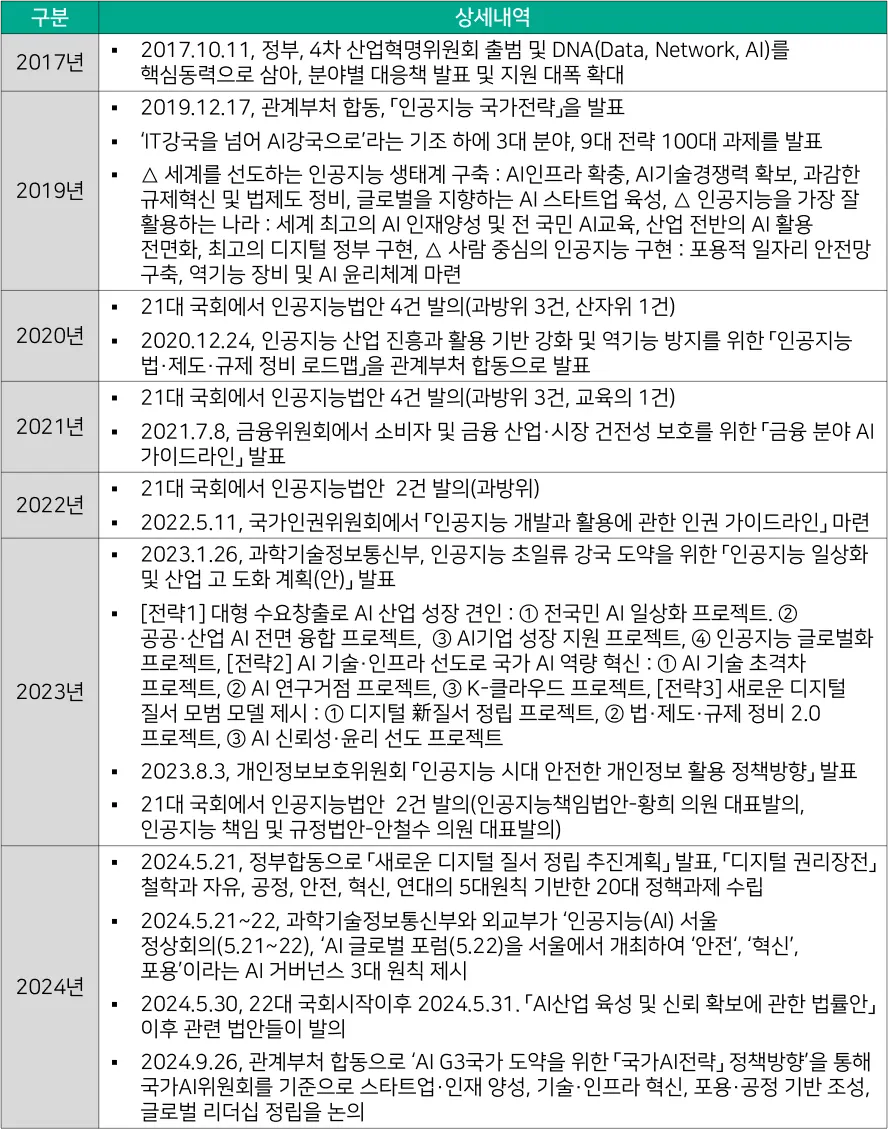
[대응기술 표 2-7] 국내 인공지능 관련 제도적 대응현황