
02. AI 에이전틱 보안을 통한 AI 레질리언스 강화
2026년 보안 위협 전망의 ‘악성 LLM 서비스로 인한 사이버 공격 보편화’에서 살펴본 바와 같이 인공지능 기술의 발전은 비단 긍정적인 목적으로만 사용되지 않았다. ‘AI for Security’와 같이 인공지능을 이용해 기존의 보안 이슈를 해결하는 방안이 되기도 하지만, 인공지능이라는 기술로 인해 새롭게 발생하는 보안 위협으로 인해 ‘Security for AI’가 필요한 상황이 되었다.
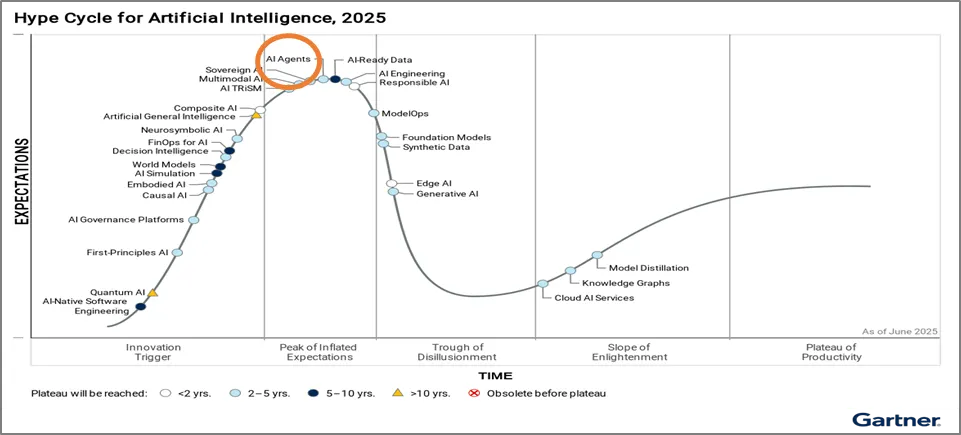
[그림 2-1]과같이 AI Agents는 ‘Gartner Hype Cycle for Artificial Intelligence, 2025’기준으로 ‘과장된 기대의 정점(Peak of Inflated Expectations)’에 위치하는 것에 비해, 기술의 확산 속도에 비해 보안 통제·거버넌스·레질리언스 체계의 성숙도가 현저히 뒤처져 있다. 특히 에이전트 기반 LLM 모델의 도구 호출, 장기 메모리, 자율 의사결정, 멀티 에이전트 연계와 같은 특성으로 인해 인간의 개입없이 실제 행위를 수행할 수 있는 공격 자동화 플랫폼으로 전락할 수 있는 위험성을 내포하고 있다.
결과적으로 공격자 측면에서는 에이전트 기술을 악용하면 지능형 피싱, 자동화된 침투 테스트, 자율적 권한상승, 실시간 보안 우회, 공격 행위 은닉 등의 수행이 가능해지면서 기존 보안체계가 설정한 위협 모델의 경계가 크게 확장된다. 기술 발전에 따라 생산성 향상이 급격히 증가하는 반면, 이를 억제하고 감시나 감사할 수 있는 보안 및 규제 메커니즘의 부재함에 따라 AI기반의 공격 확장성과 비정상적인 공격 효율성으로 인해 공격 생태계의 질적·양적 변화가 촉발할 가능성이 높다.
[그림 2-1] Gartner Hype Cycle for Artificial Intelligence, 2025
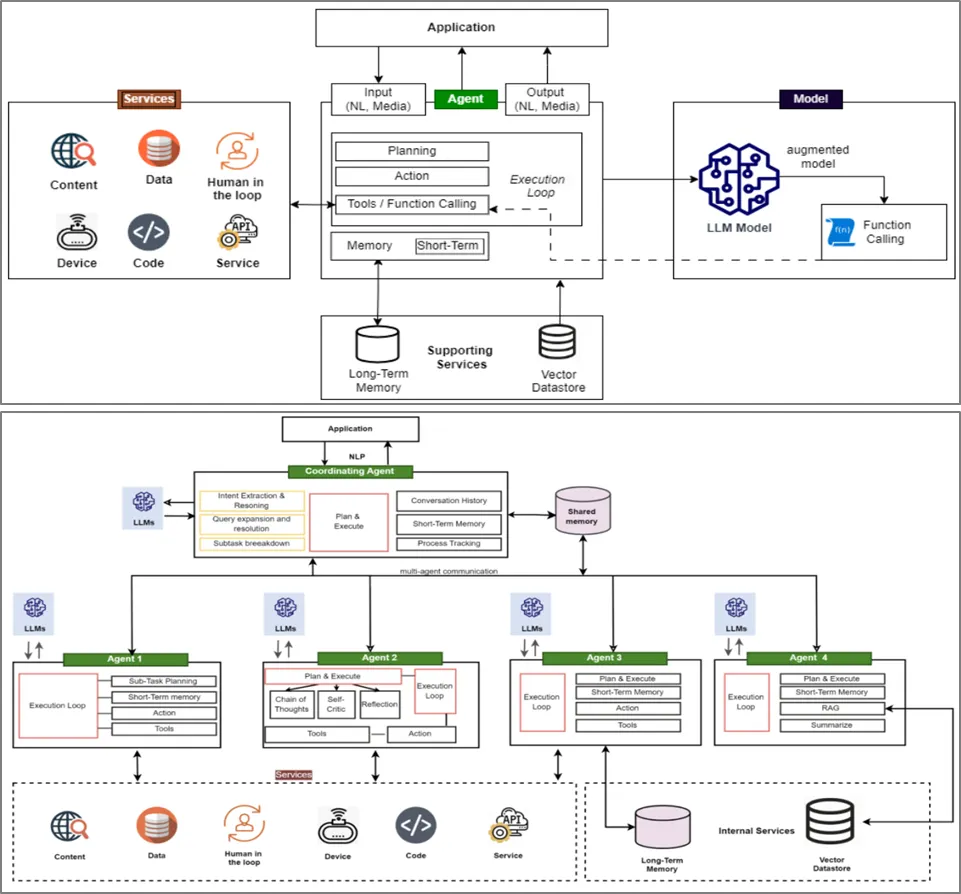
Agentic AI는 자율적 의사결정과 도구 사용을 통해 메모리를 유지가 가능하다. Autonomous하도록 설계된 Intelligent software system으로 Autonomy와 도구 사용 능력이 강화된 구조로는 특히 에이전트의 메모리나 도구 통합으로 인해 메모리 오염 및 도구 오용 등의 취약점 발생소지 증가하고 있다. 기존 LLM과 다르게 메모리 오염, 도구 오남용, 권한 탈취, Indirect Prompt Injection, Shadow Agents, 인간의 행위 조작, Model Extraction, 데이터 유출 및 민감정보 노출 등의 신규 보안 위협 발생할 소지가 높아졌다.
[그림 2-2]와같이 에이전트의 구조나 규모에서 일부 차이가 발생할 소지가 있으나 에이전트가 환경을 인식하고 추론하며 결정을 내리고 행동 계획을 수립하는 핵심 능력과 관련된 추론의 위협이나 에이전트가 외부 서비스 및 API, 코드 생성 등을 위해 도구를 호출하는 능력과 관련된 위협인 도구 실행이나 권한과 관련된 위협은 새로운 공격 벡터로 작용할 수 있다.
[그림 2-2] Single Agent Architecture와 Multi-agent Architecture (출처 : OWASP)
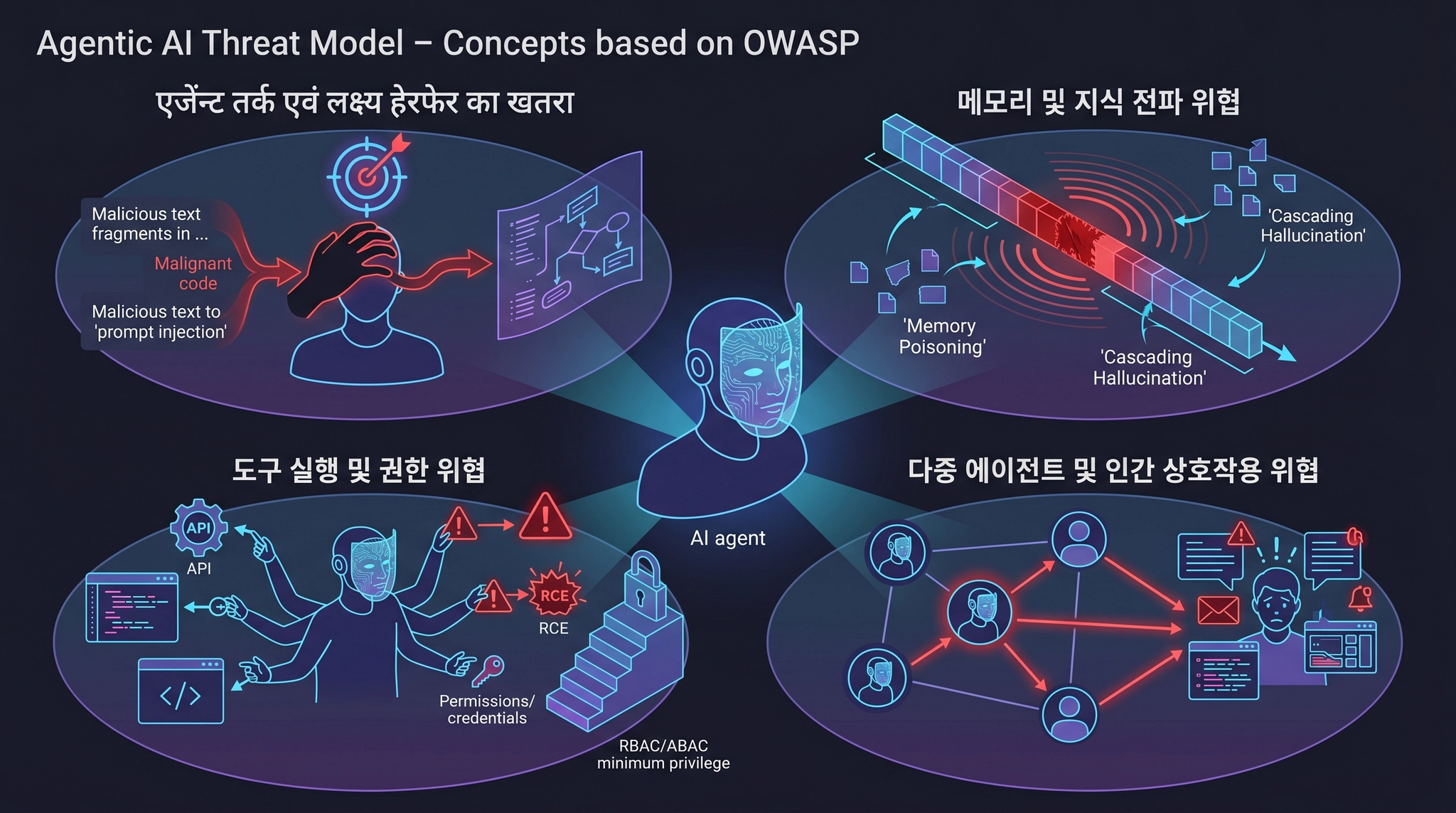
OWASP에서는 Agentic AI환경에서 발생할 수 있는 보안 위협 15가지 공개를 담은 ‘Agentic AI - Threats and Mitigations : OWASP Top 10 for LLM Apps & Gen AI Agentic Security Initiative, Version 1.0 February 2025’를 공개했다. 해당 취약점은 에이전트 추론, 메모리 및 지식 전파, 도구 실행 및 권한 관련 위협, 다중 에이전트 및 인간 상호작용 관련 위협이 발생하기 때문에 RBAC과 ABAC기반 최소권한 적용, 투명성과 책임성, 지속적인 모니터링과 행동 프로파일링이 필요하다.
[표 2-1]에서 설명된 바와 같이 에이전트의 추론 및 목표 관련 위협은 에이전트가 목표를 설정하고 계획을 수립하는 자율적인 핵심 기능을 표적으로 삼는 공격으로서 의도 파괴 및 목표 조작, 잘못 정렬된 및 기만적 행동, 부인 및 추적 불가능성 등과 같이 공격자아 프롬프트 인젝션이나 손상된 데이터 손상 등을 통해서 +유해하거나 허용되지 않은 행동으로 위협이 된다.
메모리 및 지식 전파 관련 위협은 에이전트가 결정을 내리기 위해 단기 또는 장기 메모리를 활용하는 방식과 관련된 위협이며, 이는 기존 LLM보다 영구적인 위험을 초래하게 된다. 메모리 오염이나 케스케이딩 환각 공격을 통해서 허위 정보로 인해 정상적인 의사결정을 방해하거나 실시간으로 에이전트 메모리를 오염시킬 수 있다.
도구 실행 및 권한 관련 위협은 에이전트가 외부 서비스, API, 코드 생성 등을 위해 도구를 호출하는 자율적인 능력과 관련된 위협으로 도구 오용이나 권한 침해, 예기치 않은 RCE 및 코드 공격을 통해서 악의적인 AI 생성 코드 실행이 발생하거나 외부 서비스 종속성 등으로 인해 시스템 성능이 저하될 수 있다. 다중 에이전트 및 인간 상호작용 관련 위협은 다중 에이전트 아키텍처 및 에이전트와 인간의 상호 작용에서 발생하는 고유한 위협으로 인간의 의사결정이 의도하지 않은 결과를 초래하게 할 수 있다.
[그림 2-3] Agentic AI Threat Model (출처 : OWASP)
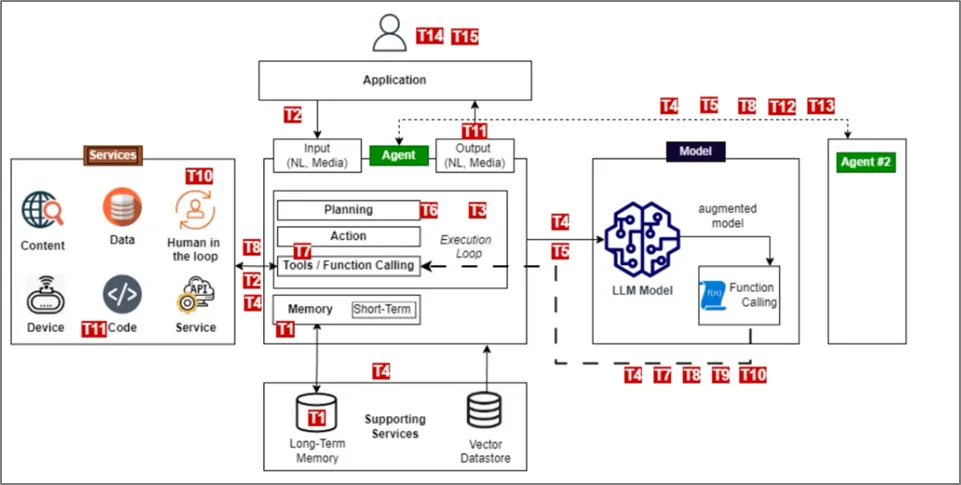
[표 2-1] Agentic AI Threat Model (출처 : OWASP)
TID | Threat Name | Threat Description | Priority | Rationale for Prioritization |
T1 | Memory Poisoning | Memory Poisoning involves exploiting an AI’s memory systems, both short and long-term, to introduce malicious or false data and exploit the agent’s context. This can lead to altered decision-making and unauthorized operations. | HIGH | Persistent impact on decision-making quality; difficult to detect once memory is corrupted; can affect all future agent operations |
T2 | Tool Misuse | Tool Misuse occurs when attackers manipulate AI agents to abuse their integrated tools through deceptive prompts or commands, operating within authorized permissions. This includes Agent Hijacking, where an AI agent ingests adversarial manipulated data and subsequently executes unintended actions, potentially triggering malicious tool interactions. For more information on Agent Hijacking see https://www.nist.gov/news. | CRITICAL | High likelihood of occurrence; immediate system impact; relatively easy to exploit through prompt manipulation; core attack vector |
T3 | Privilege Compromise | Privilege Compromise arises when attackers exploit weaknesses in permission management to perform unauthorized actions. This often involves dynamic role inheritance or misconfigurations. | CRITICAL | Severe access control implications; common misconfiguration risk in dynamic systems; enables further attack escalation |
T4 | Resource Overload | Resource Overload targets the computational, memory, and service capacities of AI systems to degrade performance or cause failures, exploiting their resource-intensive nature. | MEDIUM | Primarily availability impact; existing DoS protections partially applicable; limited business-critical consequences |
T5 | Cascading Hallucination Attacks | These attacks exploit an AI’s tendency to generate contextually plausible but false information, which can propagate through systems and disrupt decision-making. This can also lead to destructive reasoning affecting tools invocation. | HIGH | Amplifies misinformation across systems; difficult to detect plausible false information; systemic cascading impact |
T6 | Intent Breaking & Goal Manipulation | This threat exploits vulnerabilities in an AI agent’s planning and goal-setting capabilities, allowing attackers to manipulate or redirect the agent’s objectives and reasoning. One common approach is Agent Hijacking mentioned in Tool Misuse. | CRITICAL | Fundamental compromise of agent’s core purpose; high business impact; undermines entire system integrity |
T7 | Misaligned & Deceptive Behaviors | AI agents executing harmful or disallowed actions by exploiting reasoning and deceptive responses to meet their objectives. | MEDIUM | Emerging threat with detection methods still maturing; requires sophisticated AI behavior analysis; theoretical risk level |
T8 | Repudiation & Untraceability | Occurs when actions performed by AI agents cannot be traced back or accounted for due to insufficient logging or transparency in decision-making processes. | HIGH | Critical for compliance and forensic investigations; undermines accountability frameworks; regulatory implications |
T9 | Identity Spoofing & Impersonation | Attackers exploit authentication mechanisms to impersonate AI agents or human users, enabling them to execute unauthorized actions under false identities. | HIGH | Violates fundamental trust boundaries; enables privilege escalation; difficult to distinguish from legitimate behavior |
T10 | Overwhelming Human in the Loop | This threat targets systems with human oversight and decision validation, aiming to exploit human cognitive limitations or compromise interaction frameworks. | MEDIUM | Human factors vulnerability; gradually exploitable; existing UI/UX patterns provide some protection |
T11 | Unexpected RCE and Code Attacks | Attackers exploit AI-generated execution environments to inject malicious code, trigger unintended system behaviors, or execute unauthorized scripts. | CRITICAL | Direct system compromise potential; high technical impact; immediate security control bypass |
T12 | Agent Communication Poisoning | Attackers manipulate communication channels between AI agents to spread false information, disrupt workflows, or influence decision-making. | MEDIUM | Specific to multi-agent deployments; requires sophisticated attack coordination; limited current deployment scope |
T13 | Rogue Agents in Multi-Agent Systems | Malicious or compromised AI agents operate outside normal monitoring boundaries, executing unauthorized actions or exfiltrating data. | HIGH | Classic insider threat model applied to AI; difficult detection in complex distributed systems; stealth capability |
T14 | Human Attacks on Multi-Agent Systems | Adversaries exploit inter-agent delegation, trust relationships, and workflow dependencies to escalate privileges or manipulate AI-driven operations. | MEDIUM | Requires multi-agent deployment context; complex attack chain dependency; limited immediate applicability |
T15 | Human Manipulation | In scenarios where AI agents engage in direct interaction with human users, the trust relationship reduces user skepticism, increasing reliance on the agent’s responses and autonomy. This implicit trust and direct human/agent interaction create risks, as attackers can coerce agents to manipulate users, spread misinformation, and take covert actions. | HIGH | Exploits inherent user trust in AI systems; immediate social engineering risk; difficult user education challenge |
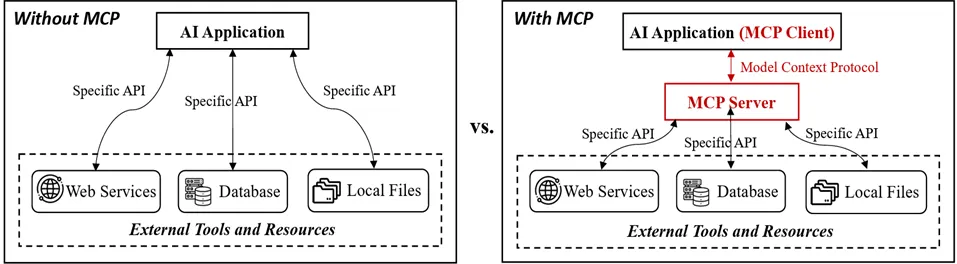
LLM과 에이전트를 위한 API, 서비스 및 도구와의 상호 작용을 위해 MCP를 통한 Agentic AI 구현으로 보안 위협 심화되고 있다. ‘Model Context Protocol (MCP): Landscape, Security Threats, and Future Research Directions’에 따르면 [그림 2-4]와같이 MCP 생명주기에 따라서 백도어, 권한상승, 설치 프로그램 스푸핑, 구성 드리프트 등의 위협이 발생한다.
[그림 2-4] MCP유무에 따른 공격벡터 비교(출처 : Model Context Protocol (MCP): Landscape, Security Threats, and Future Research Directions)
`25년 8월, 바이브 해킹을 통해 국가 지원 해킹그룹이 AI를 복잡한 사이버 공격을 수행하는 주체로 활용한 사례를 ‘Detecting and countering misuse of AI: August 2025’를 토해 공개했다. 보고서에 따르면 대규모 데이터 탈취, DPRK IT Worker, AI기반 RaaS등 범죄 공급망 전반에 활용되면서 AI가 사이버 범죄의 장벽을 낮추고 작전 규모를 확장하는데 주도적인 역할을 담당하는 것으로 나타났다.
[표 2-2] 국가지원 사이버 그룹에서 바이브 해킹을 사용한 공격 사례(출처 : Anthropic)
공격구분 | 공격기법 | AI 활용현황 |
에이전트형 AI 시스템을 활용한 데이터 갈취
(GTG-2002) | 정찰 및 타겟 발견 | •여러 기술 전반의 인프라 정보를 체계적으로 수집하는 포괄적인 스캐닝 프레임워크 생성하여 수천 개의 VPN 엔드포인트를 스캔하여 취약한 시스템을 높은 성공률로 식별 |
초기 접근 및 자격 증명 탈취 | •라이브 네트워크 침투 중 실시간 지원 제공하고 도메인 컨트롤러 및 SQL 서버를 포함한 주요 시스템을 체계적으로 스캔하여 여러 자격 증명 세트 추출 | |
악성코드 개발 및 회피 | •Windows Defender 탐지를 회피하기 위해 Chisel 터널링 도구의 난독화 버전을 생성하고, Chisel 라이브러리를 전혀 사용하지 않는 새로운 TCP 프록시 코드 개발
•문자열 암호화, 안티-디버깅 코드, 파일명 위장(MSBuild.exe, devenv.exe 등 합법적인 Microsoft 도구로 위장)과 같은 새로운 회피 기법 제공 | |
데이터 유출 및 분석 | •방위 산업체, 의료 서비스 제공업체, 금융 기관을 포함한 여러 조직에서 민감 정보(사회보장번호, 은행 계좌, 환자 정보 등)를 체계적으로 추출 및 분석 | |
탈취기법 및 랜섬노트 | •유출된 데이터를 기반으로 맞춤형 랜섬 노트를 생성
•금융 분석을 기반으로 최적의 몸값 금액을 계산하고, 피해 조직의 취약점과 규제/평판 위협에 맞춰 심리적으로 조작된 탈취 자료를 자동 생성 | |
AI 기반 RaaS 개발 및 판매
(GTG-5004 영국 TA) | 악성코드 핵심 개발 | •암호화 알고리즘이나 Windows 내부 조작 기술에 대한 독립적인 구현 능력이 부족했으나 AI를 통해 점진적으로 기능성 악성코드 개발 |
회피 및 안티-분석 | •RecycledGate 및 FreshyCalls 기법을 사용하여 사용자 모드 API Hook을 우회하는 직접 syscall 호출 구현하고, 난독화(String obfuscation) 및 안티-디버깅(Anti-debugging) 기법을 사용 | |
암호화 및 안티-복구 | •ChaCha20 스트림 암호 구현 및 RSA 키 관리 기법과 Windows 볼륨 섀도 복사본을 삭제하는 안티-복구 메커니즘 포함 | |
상업적 인프라 | •PHP 콘솔 및 C&C 도구를 포함한 RaaS 키트를 구축하여 800~1,200 USD에 판매 | |
러시아어 사용 개발자 사례 (추가) | •사용자 응대문제 해결, Early Bird 프로세스 인젝션, 텔레그램 봇 기반 C&C 인프라, 스크린샷 기능을 갖춘 데이터 유출 기능 개발 | |
DPRK IT Worker | 페르소나 개발 | •정교한 가짜 신원 생성을 위해 설득력 있는 전문 배경, 기술 포트폴리오, 경력 스토리, 그리고 현지 문화를 조사하여 진정성 있게 보이도록 지원 |
지원 및 면접 | •특정 직무 기술에 맞게 이력서를 조정하고 기술 면접 답변 준비, 코딩 평가 중 실시간 지원 | |
고용 유지 및 업무 수행 | •프런트엔드 개발(61%) 및 프로그래밍/스크립팅(26%) 작업을 AI의 단계별 지침에 의존하여 수행함으로써 기술적 능력 시뮬레이션 | |
커뮤니케이션 | •전문적인 이메일 및 메시지 작성, 기술적 설명 구성, 직장 규범 및 문화적 맥락 이해를 AI에 의존 | |
중국 위협행위자의 AI활용 | 작전 전반 통합 | •MITRE ATT&CK 전술 14개 중 거의 모든(12개) 단계에 Claude를 기술 자문가, 코드 개발자, 보안 분석가, 운영 컨설턴트로 통합 |
정찰 및 초기 접근 | •베트남 IP 범위 정찰을 위한 맞춤형 Python 스캐닝 도구 개발하고 정교한 파일 업로드 퍼징 도구 및 WordPress 익스플로잇 프레임워크 생성 | |
자격 증명 및 권한 상승 | •Hydra 및 hashcat과 같은 도구를 사용하여 자격 증명 탈취 작전 최적를 위해 Linux 커널 취약점을 포함한 권한 상승 익스플로잇 구현 | |
운영 보안 | •작전 보안을 위한 프록시 체인 구성 구축 | |
AI를 활용한 공격 공급망 통합 | 스틸러 로그 분석 및 프로파일링 | •MCP(Model Context Protocol)와 Claude를 활용하여 스틸러 로그 파일 처리. 도메인 방문 빈도 분석 및 온라인 활동을 기반으로 행동 프로파일을 구축하여 피해자 우선순위를 정교하게 결정 |
카드 사기 스토어 운영 | •Claude Code를 사용하여 세 개의 카드 검증 서비스 사이에서 순환하는 다중 API 복원력 프레임워크 구현하고 탐지를 회피하기 위한 지능적인 요청 조절 및 전략적 배치 처리 설계 | |
로맨스 스캠 봇 | •Claude를 "높은 감성 지능(high EQ)" 응답 생성에 활용하여 비모국어 사용자가 언어적 위험 신호를 우회하고 설득력 있는 메시지를 작성할 수 있도록 지원 | |
합성 신원 서비스 | •인프라의 다양한 구성 요소를 Claude를 사용하여 개발하고 운영 가능한 합성 신원 서비스 출시 |
이후 Anthropic은 중국 위협 행위자(GTG-1002)가 공격 생명주기 전반에 걸쳐 AI를 적용한 최초 사례 보고했다. ‘Disrupting the first reported AI-orchestrated cyber espionage campaign, November 2025’에 따르면 약 30개 주요 기관 및 기업을 대상으로 진행된 이 작전이 중국이 지원하는 조직인 GTG-1002에서 Claud Code를 통해 인간의 개입이 거의 없이 자율적인 침투 테스트 자동화를 구현한 것이 나타났다. 이는 `25년 8월 공개된 바이브 해킹을 넘어 Agentic AI 해킹 가능성을 증명하면서 방어 패러다임의 변화가 필요하다는 것을 의미한다. 이와 같은 사이버 스파이 활동은 위협 행위자가 첨단 AI를 사용해서 해킹 공격의 근본적인 변화가 일어난다는 것을 의미한다.
사이버 공격 캠페인은 정찰, 취약점 발견, 익스플로잇, 측면이동, 자격증명 수집, 데이터 분석 및 데이터 유출 작업 전반에 AI가 공격 통합과 자율성을 발휘하고 있다. 위협 행위자가 Claude Code를 조작해서 전체적인 공격에서 80~90%가량을 자율적으로 구성하였으며, 이 과정에서 인간의 개입이 불과 10~20%밖에 참여하지 않는 성과를 보였다. 결국 의사결정을 하는 영역에서만 인간이 개입되고 그 외의 항목에서는 인간의 개입 없이도 침투 테스트 오케스트레이션과 에이전트를 구성할 수 있다.
공격 행위 전반은 인간의 개입없이 실행될 뿐만 아니라 사이버 공격 행위 전반이 명문화되었다. 자율적으로 취약점을 발견하고 실제 공격 현장에서 악용하면서 주요 기업이나 정부 기관에 효과적으로 접근하는 것이 가능한다. 이 과정에서 공격의 속도를 초당 다수의 오퍼레이션을 수행할 수 있는 공격 체인을 구성했다는 점에서 사이버 공격의 자동화가 이뤄지면서 고도화된 사이버 공격에 대한 진입장벽을 크게 낮추면서 AI 안전장미 마련의 시급성을 역설하고 있다.
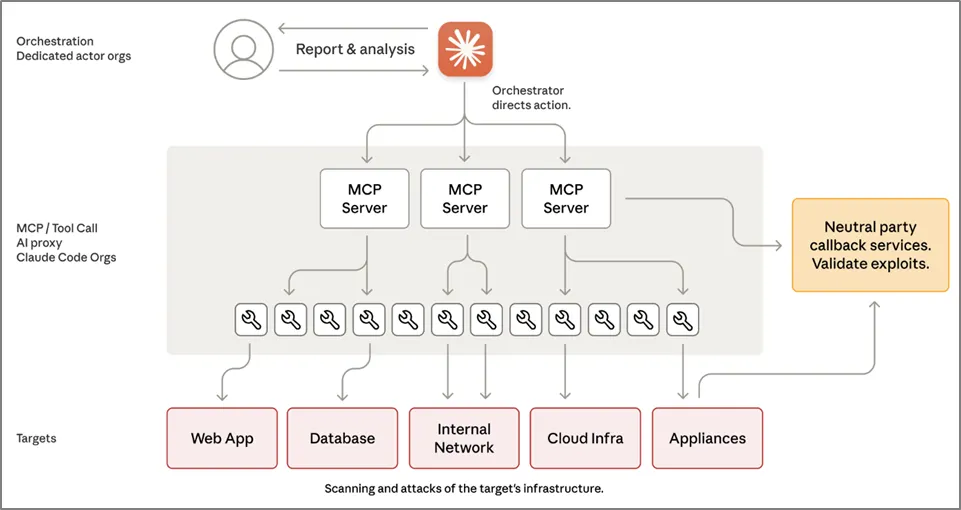
[그림 2-7] Claude Code를 이용한 MCP 아키텍처 구성 (출처 : Anthropic)
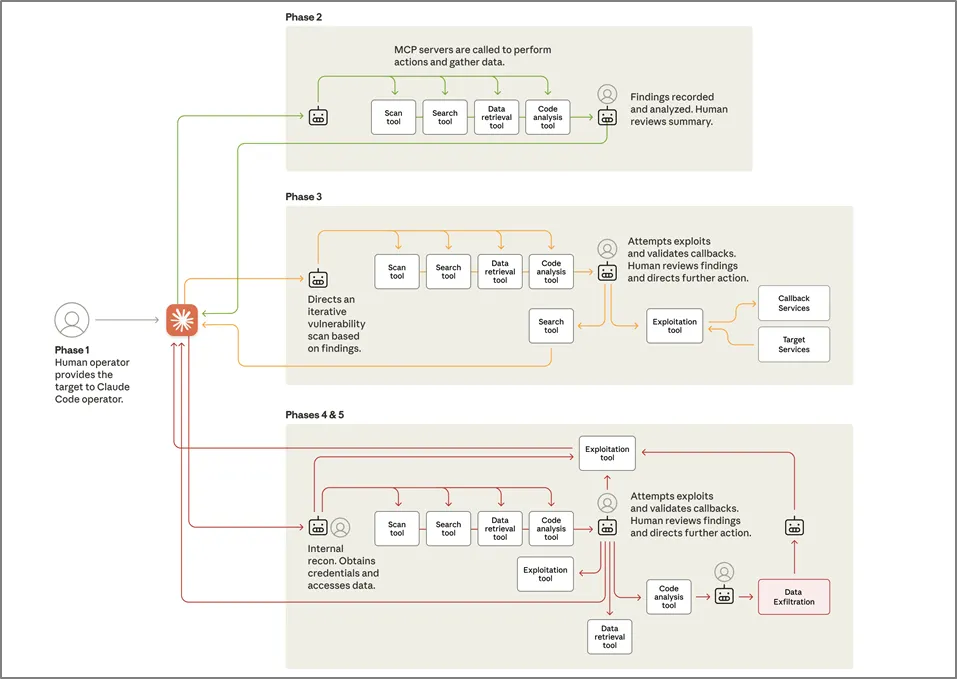
GTG-1002 작전은 AI의 자율성이 공격 수명주기 전반에 걸쳐 전례 없이 통합되었음을 보여주는 구조화되어 [그림 2-8]과 같이 6단계로 진행된다. 1단계 캠페인 초기화 및 대상 선정에서는 주요 기술 기업, 금융 기관, 화학 제조 회사, 여러 국가의 정부 기관 등 공격 대상을 입력하여 사회공학적 기법을 이용해서 Claude를 사회공학적 기법을 통해서 설득해서 공격에 참여하게 한다. 이를 기반으로 오케스트레이션 엔진은 Claude에서 여러 대상에 대해 병렬로 자율 정착을 시작하도록 구성된다.
2단계에서는 정찰 및 공격 표면 매핑을 진행한다. Claude는 위협 행위자의 지시에 따라서 거의 자율적인 정착을 수행한다. MCP를 통해 브라우저 자동화 같이 여러 도구를 사용해서 인프라를 체계적으로 분류하고 인증 메커니즘을 분석해서 잠재적인 취약점을 식별하면서 여러 대상에 걸쳐 동시다발적으로 공격을 진행한다. 3단계에서는 AI가 자동화된 테스팅을 통해 익스플로잇을 진행하면서 맞춤형 페이로드를 작성하거나 익스플로잇 체인을 개발하여 공격 대상 시스템내에 거점을 확보한다.
4단계에서는 Claude가 인간의 승인을 득한 후에 공격 대상 네트워크 전반에 걸쳐 자격증명을 수립한다. 특히 내부 서비스 쿼리, 구성파일에서 인증서 추출 등 독립적인 판단을 통해 매핑을 하는 작업을 수행하게 된다. 5단계에서는 데이터 수집 및 정보 추출을 수행하여 마지막 6단계를 통해서 문서화를 수행하게 된다.
[그림 2-8] Claude Code를 이용한 공격 단계 (출처 : Anthropic)
[표 2-3] Claude Code를 이용한 AI 자동화 공격 단계별 역할 (출처 : Anthropic)
공격 단계 | AI 활용현황 |
1. 캠페인 초기화 및 대상 선정 | •주요 기술 기업, 금융기관, 화학제조기업, 여러 국가정부기관 등 공격대상을 입력하여 캠페인 시작
•사회공학적 기법을 이용해 Claude를 설득해서 공격에 참여하도록 설득(합법적인 사이버 보안 회사 직원이라고 주장)
•Claude에게 여러 대상에 대해 병렬적으로 자율 정찰을 시작하도록 작업 지시를 하며 초기 단계에서는 AI역할보다는 인간의 역할이 강화 |
2. 정찰 및 공격 표면 매핑 | •Claude는 위협 행위자의 지시에 따라 거의 자율적인 정찰을 수행
• MCP(Model Context Protocol)를 통한 브라우저 자동화와 같은 여러 도구를 사용하여 대상 인프라를 체계적으로 분류하고, 인증 메커니즘을 분석하며, 잠재적인 취약점을 식별
•AI가 각 활성 캠페인에 대한 별도 운영 컨텍스트를 유지하면서 여러 대상에 걸쳐 동시에 공격 캠페인 진행
•Claude가 인간의 개입 없이 내부 서비스를 자율적으로 발견하고 여러 IP 범위에 걸쳐 완전한 네트워크 토폴로지를 매핑하며, 데이터베이스 및 워크플로 오케스트레이션 플랫폼을 포함한 고가치 시스템을 식별 |
3. 취약점 발견 및 검증 | •Claude는 식별된 공격 표면에 대한 자동화된 테스트를 통해 익스플로잇을 진행
•Claude는 발견된 취약점에 맞춘 공격 페이로드를 독립적으로 생성하고, 원격 명령 인터페이스를 통해 테스트를 실행하며, 콜백 통신 시스템을 통해 응답을 분석하여 익스플로잇 가능성을 검증
•타겟 인프라 스캐닝, 서비스 및 엔드포인트 열거를 통한 공격 표면 매핑 > SSRF 취약점 식별 및 익스플로잇 기술 연구 > 맞춤형 페이로드 작성 및 공격체인개발(콜백 응답에 따른 익스플로잇 유효성 검증) > 최초 접근을 위한 익스플로잇 배포 및 환경 내 거점 확보(AI, 1~4시간 소요)
•AI가 포괄적인 발견 사항을 문서화하면, 이를 검토하고 능동적인 익스플로잇 단계로의 상승을 승인하는 전략적 감독 역할을 수행(인간, 2~10분 소요) |
4. 자격 증명 수집 및 측면 이동 | •인간의 승인 이후 Claude는 대상 네트워크 전반에 걸쳐 체계적인 자격 증명 수집을 실행
•내부 서비스 쿼리, 구성 파일에서 인증 인증서 추출, 수집된 자격 증명을 발견된 시스템 전반에 걸쳐 테스트하는 과정이 포함되며, Claude는 인간의 지시 없이 어떤 자격 증명이 어떤 서비스에 접근 권한을 제공하는지 독립적으로 판단하고 권한 수준을 매핑
•훔친 자격 증명을 사용하여 접근 가능한 시스템을 AI가 지시하여 열거하는 방식으로 측면 이동이 진행되는데 AI는 내부 API, 데이터베이스 시스템, 컨테이너 레지스트리 등을 체계적으로 테스트하여 내부 네트워크 아키텍처 및 접근 관계에 대한 포괄적인 구조를 구축 |
5. 데이터 수집 및 정보 추출 | •위협 행위자는 Claude에게 데이터베이스와 시스템에 독립적으로 쿼리하고 데이터를 추출해 결과를 구문 분석하여 독점 정보를 식별하고 정보 가치별로 분류하도록 지시한 내용에 따라 AI 자율성을 토대로 AI 스스로 활동(AI, 2~6시간 소요)
•AI는 방대한 양의 데이터를 처리하여 자동으로 가치 있는 정보를 식별하고 인간의 분석을 요구하지 않은 상태에서 최종 데이터 유출 승인단계에서만 인간의 개입을 요청(5~20분)
•모든 캠페인 단계를 문서로 자동 생성하여 구조화된 마크다운 파일에는 발견된 서비스, 수집된 자격 증명, 추출된 데이터, 익스플로잇 기술 및 완전한 공격 진행 상황 등이 추적할 수 있도록 하였으며 후속 활동에 대한 전략적 의사결정을 지원 |
 IGLOO Corp. 2025. All rights reserved.
IGLOO Corp. 2025. All rights reserved.