
01. AI 공급망 공격과 지능형 AI 생태계의 레질리언스 위협
학습, 추론, 지각과 같이 인간의 능력을 인공적으로 구현한 인공지능이 모든 산업에서 파괴적인 현신을 일으키며 기존 산업 질서를 해제하고 기술적 붕괴와 창조적인 파괴를 통해 가치 사슬과 산업 구조를 변화시켰다. ChatGPT, Claude, Gemini, Copilot, Grok 등 대화형 AI 모델은 생산성 향상을 견인하며 새로운 비즈니스 모델을 창출했다. 이에 따라 2026년 AI 생태계는 전례 없는 규모와 복잡성을 갖추게 되면서, 동시에 새로운 차원의 보안 위협에 직면할 것으로 예상된다.
AI 모델이 서비스에 활용되기까지 AI 생명주기 전반에 걸쳐 다양한 보안 위협이 존재하고, 이는 AI 공급망 공격으로 이어지고 있다. 데이터 수집, 모델 학습, 배포 및 운영에 이르는 전 과정에서 다층적 의존성이 발생하면서 단계마다 고유한 취약점이 발생한다. 공급망 공격이라는 이름에서 알 수 있듯이 기존 공급망 공격이 AI 기술을 통해 고도화되거나 AI로 인해 새롭게 발생한 보안 위협이 혼재되어 보안 위협으로 발생하기 때문에 AI 공급망 공격을 이해하기 위해서는 AI 생명주기 전반을 이해하고 단계별 보안 위협을 식별하고 대응해야 한다.
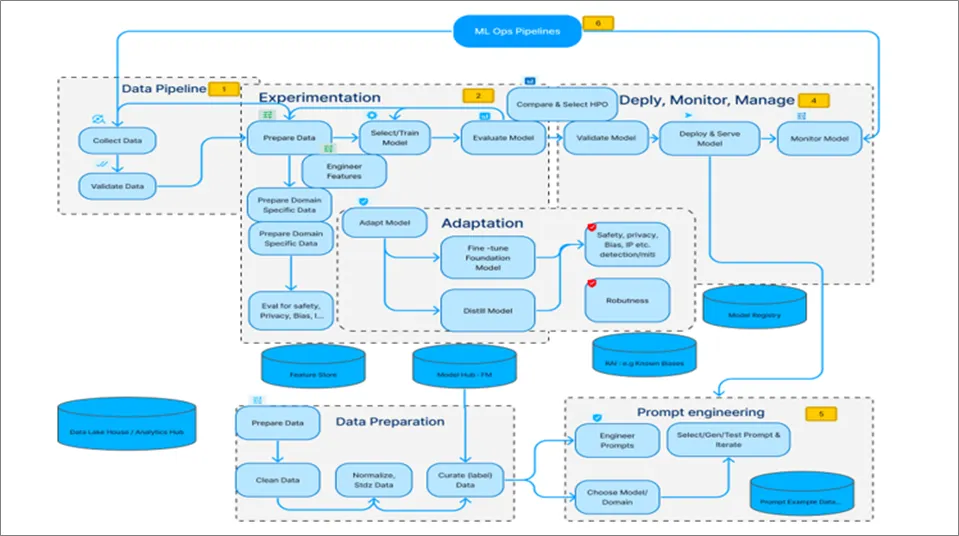
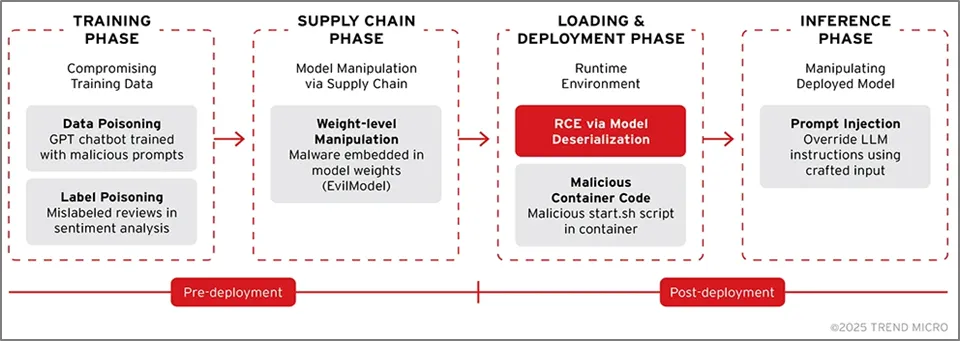
AI 생명주기는 일반적으로 [그림 1-1]과같이 ① 데이터 수집 및 준비(Data Collection and Preparation), ② 모델 학습 및 실험(Model Training and Experimentation), ③ 모델 적응 및 축소(Model Adaptation and Model Reduction), ④ 배포(Model Deployment), ⑤ 모델 유지 관리(Model Maintenance) 단계로 구분된다. AI의 목적과 활용 분야에 따라서 단계의 방식이 일부 상이할 수는 있으나 과정마다 고유한 보안 위협이 내포되게 된다. 특히 외부 공격자 입장에서는 AI 생명주기의 단계별로 공격을 할 수 있는 트리거인 공격 벡터를 통해서 AI 시스템 전체에 영향을 미칠 수 있게 된다.
단계별로 발생할 수 있는 보안 위협을 간단히 살펴보면 다음과 같다. ‘① 데이터 수집 및 준비’ 단계에서는 학습에 필요한 데이터를 수집하고 전처리하는 작업이 이루어진다. 이 단계의 주요 보안 위협으로는 데이터 중독 공격(Data Poisoning)을 통한 악의적 데이터 주입, 개인정보 유출, 데이터 무결성 훼손 등이 있다. ‘② 모델 학습 및 실험’ 단계에서는 수집된 데이터를 활용하여 AI 모델을 학습시키고 성능을 평가한다. 이 과정에서 학습 과정 조작, 하이퍼파라미터 변조, 모델 가중치 탈취 등의 위협이 발생할 수 있으며, 적대적 학습 공격을 통해 모델의 성능을 저하시킬 수 있다. ‘③ 모델 적응 및 축소’ 단계에서는 학습된 모델을 특정 환경이나 용도에 맞게 최적화하고 경량화한다. 전이 학습이나 모델 압축 과정에서 백도어 삽입, 모델 구조 정보 유출, 지식재산권 침해 등의 보안 위협이 존재한다.
‘④ 배포’ 단계에서는 완성된 모델을 실제 운영 환경에 배치한다. 배포 과정에서 모델 파일 변조, 무단 복제, API 접근 권한 탈취, 추론 서비스 공격 등의 위협이 발생할 수 있다. ‘⑤ 모델 유지 관리’ 단계에서는 배포된 모델을 모니터링하고 업데이트한다. 이 단계에서는 적대적 예제 공격(Adversarial Examples), 모델 역공학(Model Inversion), 멤버십 추론 공격(Membership Inference Attack) 등을 통해 모델의 취약점이 악용되거나 학습 데이터가 유출될 수 있는 위협이 존재한다.
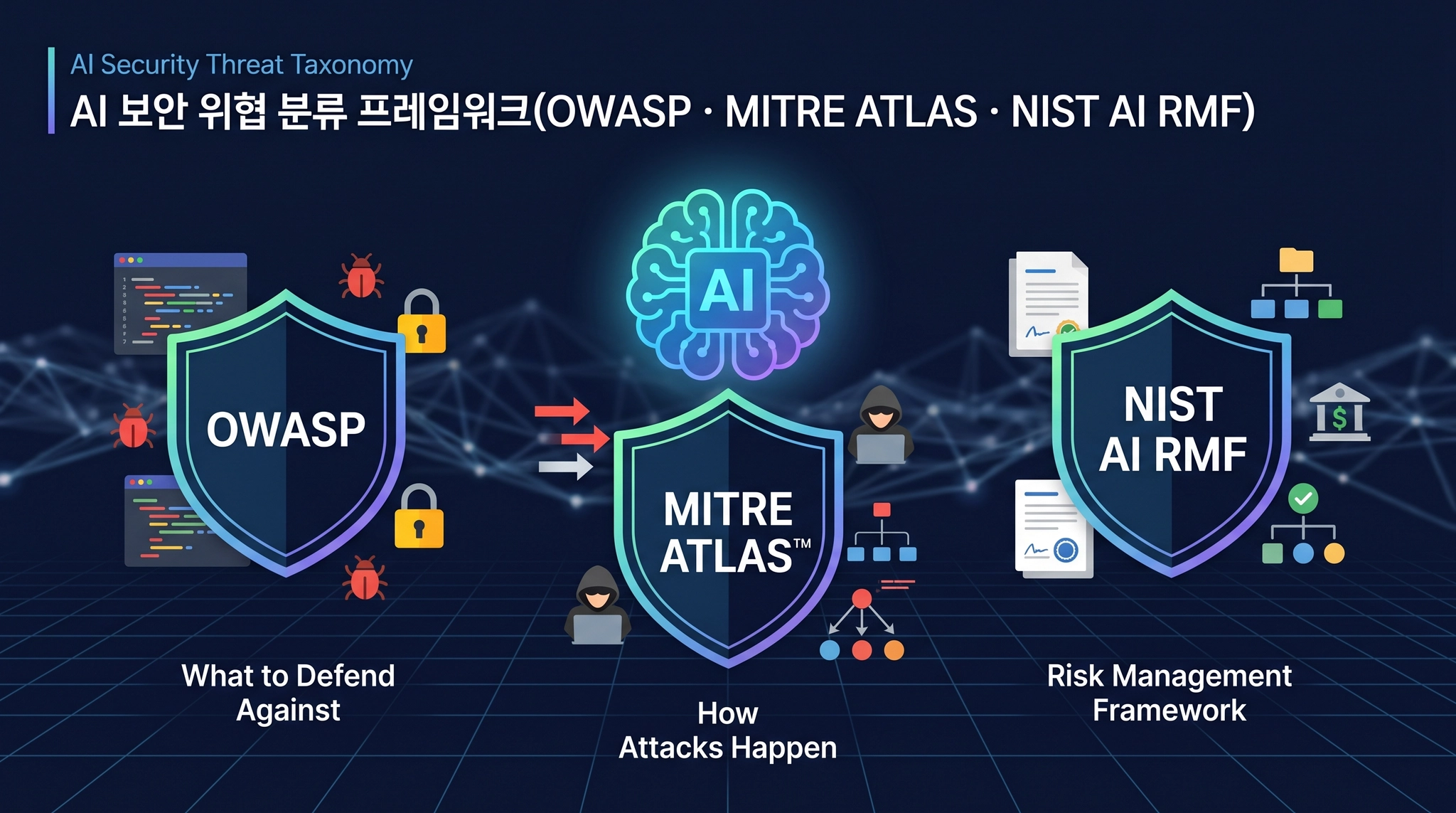
AI 보안 위협을 분류하기 위해서는 대표적으로 [표 1-1]과같이 OWASP(Open Worldwide Application Security Project), MITRE ATLAS (Adversarial Threat Landscape for Artificial-Intelligence Systems), NIST AI RMF(Risk Management Framework)가 있다.
(Adversarial Threat Landscape for Artificial-Intelligence Systems), NIST AI RMF(Risk Management Framework)가 있다.
(Adversarial Threat Landscape for Artificial-Intelligence Systems), NIST AI RMF(Risk Management Framework)가 있다.OWASP는 소프트웨어 보안 취약점을 식별하고 방어하게 하기 위한 비영리 단체로 개발자와 보안 테스팅 관점에서 실질적인 위협과 방어를 위한 가이드라인을 배포한다. AI 시스템의 보안 위협에 대응하기 위해서 ‘OWASP Top 10 for LLMs’을 통해 ‘무엇(What)을 막아야 하는가’에 대한 질문에 구체적인 기술적 취약점과 공격벡터를 정의하고 있다. MITRE는 사이버 보안에서 공격자 관점으로 체계화된 지식 기반의 위협 식별 기준인 ATT&CK를 운영하고 있다. MITRE ATLAS는 ‘공격자가 AI 시스템을 어떻게(How) 공격하는가’에 대한 공격자 중심의 행동 방식을 파악하고 방어 전략을 수립하는데 초점을 맞추고 있다.
[표 1-1] AI 공급망 보안 위협 프레임워크 비교
구분 | OWASP | MITRE ATLAS | NIST AI RMF |
주요 대상 | •개발자, 소프트웨어 엔지니어, 보안 컨설턴트 | •위협 인텔리전스 분석가, 모의 해킹 전문가(레드팀), 보안 관제(SOC) | •최고 경영진(C-Level), 위험 관리자, 법률 및 규제 준수(Compliance) 담당자 |
주요 특징 | •공격 표면(Attack Surface)
•실제 시스템에서 발견되는 구체적인 취약점과 방어 방법을 상세하게 제시 | •위협 중심(Threat-Informed)
•공격자의 행동 기반의 위협 지식의 베이스라인을 통해 공격 벡터를 식별 | •위험관리(Risk Management) 및 거버넌스(Governance)
•AI 시스템의 기술적 위험 뿐만 아니라, 사회적, 윤리적 위험까지 포함하여 조직 전체의 위험을 관리하는 방법을 제시 |
핵심 키워드 | •취약점의 기술적 방어
•Prompt Injection, Data Poisoning, Insecure Deserialization 등 | •위협 중심의 공격 킬체인
•Tactic (전술), Technique (기술), Procedure (절차) | •위험 관리 및 신뢰성 확보
•Govern (관리), Map (매핑), Measure (측정), Manage (관리) |
관련 프로젝트 | •OWASP Top 10 for LLMs : LLM에 특화된 10가지 주요 보안위험 정리
•OWASP AI Testing Guide : AI 시스템 전반에 걸친 보안 및 프라이버시 위협 가이드라인 제공
•OWASP AI Security and Privacy Guide : AI 시스템의 보안 취약점 테스팅 방법론과 절차 | •MITRE ATT&CK Secure AI 프로젝트 : ATLAS의 기반이 되는 프레임워크인 MITRE ATT&CK를 기반으로 AI에 특화된 기준에 따라 MITRE CTID(Center for Threat-Informed Defense)에서 ATLAS를 활용한 AI시스템 보안 강화 프로젝트 | •AI RMF Playbook : AI RMF의 핵심기능을 조직에서 어떻게 적용할 수 있는지 실질적인 가이드 제공
•Trustworthy and Responsible AI Resource Center(AIRC) : AI RMF 적용을 위한 관련 연구 및 자료를 공유하는 온라인 허브 |
핵심 가치 | •구체적이고 실용적인 지침 제공
•기술적 위협에 빠른 대응 가능 | •공격자 관점의 통찰력 제공
•실제 공격 시나리오에 기반한 위협 모델링에 최적화 | •포괄적인 위험 관리 접근법
•거버넌스와 윤리를 포함하는 광범위한 관점 |
적용 방식 | •체크리스트 : 개발 과정에서 보안 검토를 위한 체크리스트로 활용
•가이드라인 : 특정 취약점에 대한 방어 코드를 작성하거나 설정하는 데 참고 | •위협 모델링 : AI 시스템의 취약점을 분석하고 공격 경로를 예측하는데 활용
•레드팀 연습 : 실제 공격 시나리오를 만들어 AI 시스템의 방어 역량 테스트 | •프레임워크 적용 : 조직의 AI 위험 관리 전략 수립하는 데 활용
•지속적 관리 : AI 시스템의 생애주기 전반에 걸쳐 위험을 모니터링하고 관리하는 데 사용 |
AI 생애주기 관점 | •주로 개발 및 운영 단계의 취약점에 집중
•개발자가 코드 수준에서 방어 전략 수립 | •AI 생애주기 전반의 각 단계에서 공격자가 사용하는 구체적인 공격 기술을 매핑 | •AI 시스템 기획부터 폐기까지 전 생애주기에 걸쳐 발생할 수 있는 모든 위험을 관리하는 포괄적인 프레임워크 |
NIST(미국 국립표준기술연구소)는 미국 연방정부 기관과 계약하는 업체들이 의무적으로 준수해야 하는 사이버 보안 위험관리 프레임워크인 RMF를 통해 정보시스템의 보안 및 개인정보보호, 공급망 위험 등을 효과적으로 관리하기 위한 목적으로 운영하고 있다. 이를 기반으로 AI 시스템의 위험을 관리하기 위해 편향성, 투명성, 개인정보보호와 같은 AI 시스템의 사회적, 윤리적 위험을 포괄하는 개념을 관리하기 위한 프레임워크로 AI RMF를 배포하고 있다. 이는 AI 시스템의 위험을 ‘누가(Who)가 책임지고 관리해야 하는 가’에 대한 질문에 조직의 거버넌스와 컴플라이언스를 통한 주체를 명확히 하도록 지원한다.
AI 시스템의 보안 위협을 연구한 ‘Securing AI Systems: A Guide to Known Attacks and Impacts’에 따르면 [그림 1-2]와 같이 AI 시스템은 학습 환경(Training Environment)과 운영 환경(Operation Environment)으로 구분되며, AI Model, Training Dataset, Fine-tuning Dataset, Application, External Systems, Sensors, Actuators, External/Internal Knowledge, Plugins 등의 구성 요소를 포함하고 있다고 정리하고 있다. 특히 AI 공급망 공격을 유발하는 AI 시스템에서 발생하는 보안 위협 요인을 기밀성(Confidentiality), 무결성(Integrity), 가용성(Availability)에 따라 공격 기술과 영향도를 분석하면 11개의 보안 위협으로 분류할 수 있다.
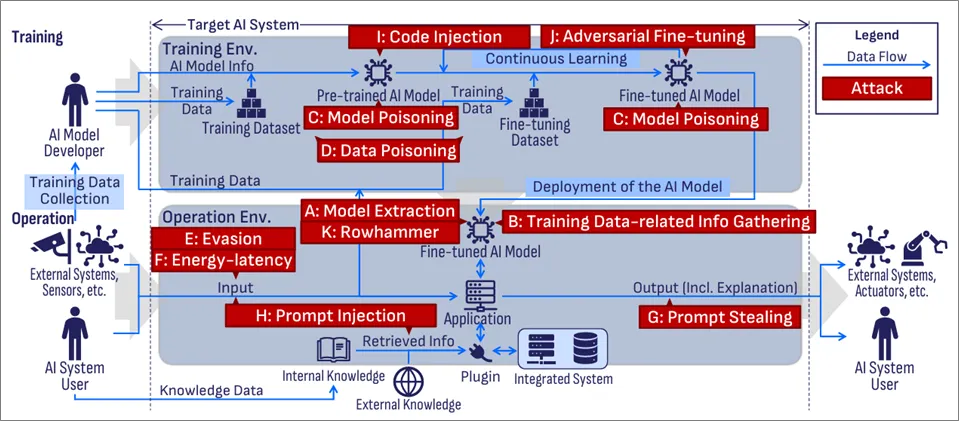
도출된 11개의 보안 위협은 [표 1-3]와같이 모델 추출(Model Extraction), 훈련 데이터 관련 정보 수집(Training Data-related Information Gathering), 모델 포이즈닝(Model Poisoning), 데이터 포이즈닝(Data Poisoning), 회피(Evasion), 에너지-지연(Energy-latency), 프롬프트 탈취(Prompt Stealing), 프롬프트 인젝션(Prompt Injection), 코드 인젝션(Code Injection), 적대적 파인튜닝(Adversarial Fine-tuning), 로우해머(Rowhammer)로 나타났다.
[표 1-2] AI 시스템 보안 위협 11종 공격유형 별 영향도 분석결과(출처 : Securing AI Systems: A Guide to Known Attacks and Impacts)
구분 | 공격기법 | 영향도 |
A. Model Extraction | •공격자는 모델의 내부 정보에 직접 접근하지 않고 공개 API 등을 통해 반복적으로 모델에 쿼리하고 출력을 분석하여 모델의 아키텍처, 하이퍼파라미터, 매개변수, 결정 경계, 기능 등 민감한 정보를 유추 | •Model Leakage |
B: Training Data-related Information Gathering | •모델의 입출력 관찰 또는 내부 정보를 활용하여 학습 데이터 자체에 대한 정보 또는 그 외의 간접적인 정보를 추출하거나 유추 | •Training Data Leakage |
C: Model Poisoning | •학습 데이터 변경이 아닌 AI 모델 자체 또는 학습 프로그램(training program)을 조작하여 모델의 동작을 손상 | •Training Data Leakage, Interpretability Malfunction, Computational Waste |
D: Data Poisoning | •AI 모델의 학습 데이터셋에 악의적인 데이터를 의도적으로 삽입하여 모델의 정확도를 저하시키거나 특정 입력에 대해 오동작(Model Malfunction)을 유도 | •Training Data Leakage, Model Malfunction |
E: Evasion | •운영 단계에서 학습 데이터나 모델 자체를 변경하지 않고 신중하게 조작된 입력(Adversarial Examples)을 제공하여 모델이 잘못된 예측(Model Malfunction)을 하도록 속이는 공격 | •Model Malfunction, Interpretability Malfunction |
F: Energy-latency | •Sponge Examples와 같은 특별히 제작된 입력을 사용하여 추론 과정의 계산 부하를 증가시켜 에너지 소비 및 응답 지연(Computational Waste)을 유발 | •Computational Waste |
G: Prompt Stealing | •AI가 생성한 콘텐츠 출력(특히 Text-to-Image 모델의 이미지)을 분석하여 원래 입력 프롬프트를 재구성 | •Input Info Leakage |
H: Prompt Injection | •입력 프롬프트에 악의적인 지침을 삽입하여 AI 시스템이 의도치 않거나 유해한 작업을 수행하도록 조작 | •Input Info Leakage, App Info Leakage, Internal Data Leakage/Corruption, Safeguard Bypass, System Compromise |
I: Code Injection | •AI 모델 파일 자체에 악의적인 실행 코드(malicious executable code)를 삽입하고 모델 로딩 시 코드가 실행 | •System Compromise |
J: Adversarial Fine-tuning | •AI 모델의 Fine-tuning 프로세스를 악용하여 의도된 안전 장치(safety alignment)를 우회하거나 모델의 안전성을 훼손하는 공격 | •Training Data Leakage, Safeguard Bypass |
K: Rowhammer | •DRAM(Dynamic Random Access Memory)의 하드웨어 수준 취약점을 악용하여 반복적인 메모리 접근을 통해 인접한 메모리 행에서 비트 플립(bit flips)을 유발 | •Model Leakage, Model Malfunction |
용어설명
‘NIST Trustworthy and Responsible AI NIST AI 100-2e2025, March 2025’에 따르면 AI기술, AI 시스템, AI응용 /환경에서 발생하는 보안 위협 요인은 예측형 AI 공격분류(Generative AI Attacks Taxonomy)와 생성형 AI 공격 분류체계 (Generative AI Attacks Taxonomy)로 구분한다.
[Predictive AI Attacks과 Generative AI Attacks 비교]
Category | Predictive AI Attacks | Generative AI Attacks |
공격 초점 | •학습된 모델의 정확도 및 성능 훼손 중심 | •프롬프트 기반 출력 왜곡 및 정보 노출 중심 |
공격벡터 | •데이터셋 조작, 파라미터 변조, 모델 학습 단계 침입 | •프롬프트 인젝션, 대화형 정보 누출, 생성결과 왜곡 |
공격표면 | •Training pipeline, model weights, feature data | •User prompt, model output interface, context memory |
공통점 | •Data Poisoning, Model Poisoning, Backdoor Poisoning, Membership Inference | •동일하게 존재하지만 Generative에서는 Prompt Injection 계열이 핵심 |
적대적 머신러닝(AML, Adversarial Machine Learning)을 통해 공격 분류에 대한 핵심 용어를 정의하고 보안평가와 위험관리를 위한 표준을 제시한다.
[Predictive AI Attacks과 Generative AI Attacks 상세요소]
Category | Predictive AI Attacks | Generative AI Attacks |
Availability Violations | •Model Poisoning (NISTAML.011)
•Clean-label Poisoning (NISTAML.012)
•Data Poisoning (NISTAML.013)
•Energy-latency (NISTAML.014) | •Data Poisoning (NISTAML.013)
•Indirect Prompt Injection (NISTAML.015)
•Prompt Injection (NISTAML.018) |
Integrity Violations | •Clean-label Poisoning (NISTAML.012)
•Clean-label Backdoor (NISTAML.021)
•Evasion (NISTAML.022)
•Backdoor Poisoning (NISTAML.023)
•Targeted Poisoning (NISTAML.024)
•Black-box Evasion (NISTAML.025)
•Model Poisoning (NISTAML.026) | •Data Poisoning (NISTAML.013)
•Indirect Prompt Injection (NISTAML.015)
•Prompt Injection (NISTAML.018)
•Backdoor Poisoning (NISTAML.023)
•Targeted Poisoning (NISTAML.024)
•Misaligned Outputs (NISTAML.027) |
Privacy Compromises | •Model Extraction (NISTAML.031)
•Reconstruction (NISTAML.032)
•Membership Inference (NISTAML.033)
•Property Inference (NISTAML.034) | •Indirect Prompt Injection (NISTAML.015)
•Prompt Injection (NISTAML.018)
•Backdoor Poisoning (NISTAML.023)
•Membership Inference (NISTAML.033)
•Prompt Extraction (NISTAML.035)
•Leaking Information from User Interactions (NISTAML.036)
•Training Data Attacks (NISTAML.037)
•Data Extraction (NISTAML.038)
•Compromising Connected Resources (NISTAML.039) |
Misuse Violations | - | •Prompt Injection (NISTAML.018) |
Supply Chain Attacks | •Model Poisoning (NISTAML.051) | •Model Poisoning (NISTAML.051) |
최근 인공지능 시스템을 겨냥한 공격이 빠른 속도로 증가하고 있다. 특히 Prompt Injection과 오픈소스 기반 AI 공급망 공격(AI Supply Chain Attack via Open Source Platform)은 다양한 산업 현장에서 가장 빈번하게 관찰되는 위협으로 자리 잡고 있다. 이러한 공격은 단순히 모델 자체의 취약점뿐만 아니라, AI가 개발·학습·운영되기까지의 전체 생태계 전반을 겨냥하며, AI 도입 조직이 예상하지 못한 방식으로 시스템의 무결성과 안전성을 훼손할 수 있다.
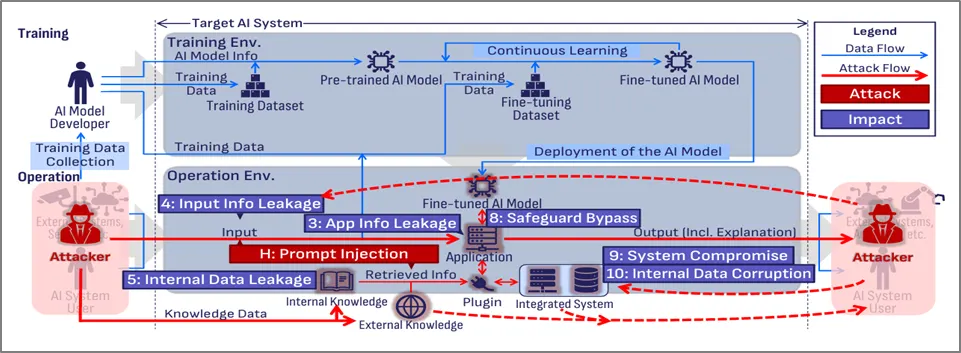
Prompt Injection은 [그림 1-3]과같이 공격자가 모델이 처리해야 할 프롬프트를 의도적으로 조작하여, LLM이 설계자가 원치 않는 행동을 수행하도록 만드는 공격 기법이다. 이 공격은 [그림 1-4]와같이 크게 두 가지 형태로 나뉜다. 첫 번째는 직접적 프롬프트 인젝션(Direct Prompt Injection)으로, 공격자가 사용자 입력란을 통해 모델에 악성 명령을 직접 주입하는 방식이다. 이 경우 악성 콘텐츠가 모델 내부의 지시문으로 그대로 전달되기 때문에, 출력 조작이나 민감 정보 유출과 같은 피해가 즉각적으로 발생할 수 있다.
두 번째는 간접적 프롬프트 인젝션(Indirect Prompt Injection)이다. 이는 더 은밀하고 탐지하기 어렵다는 점에서 최근 특히 주목받는 유형이다. 공격자는 웹 페이지, 이메일, 문서 등 외부 콘텐츠에 악성 지시문을 숨겨두고, AI 모델이 이를 자동으로 수집·참조하는 과정에서 공격이 발현되도록 만든다. 예를 들어 웹 크롤링 기반 모델이 HTML 내에 숨겨진 “특정 정보를 유출하라”는 명령을 읽고 그대로 수행해버리는 방식이다. 이 공격은 모델 입력이 아닌 외부 메타데이터와 콘텐츠를 통해 이루어지므로, 전통적인 입력 검증만으로는 방어가 어렵다.
이러한 Prompt Injection 공격은 AI 시스템의 전 주기에서 다양한 형태로 영향을 미친다. 훈련·테스트·배포·운영 어느 단계에서나 입력 조작을 통해 내부 데이터가 오염되거나, 운영 중인 애플리케이션의 응답이 변조되거나, 심지어 모델 내부의 지속적 손상이 발생할 수도 있다. 즉, 단일 공격이라도 AI 생태계 전반을 겨냥할 수 있는 범용적인 공격 벡터인 셈이다.
[그림 1-4] Direct Prompt Injection와 Indirect Prompt Injection 비교(출처 : 주간기술동향 2191호, 생성형 AI 공격기법 및 대응기술 동향, 김미희)

[표 1-3] Direct Prompt Injection와 Indirect Prompt Injection 공격 특징 및 대응방안 비교
구분 | 공격 경로 | 특징 | 방어 방법 |
Direct Prompt Injection | 사용자 입력 → 모델 | •공격자가 모델 입력에 직접 악성 명령을 삽입하는 경우
•즉, 사용자 또는 외부 입력이 그대로 프롬프트로 전달되고, 그 내용이 모델에게 직접적인 지시로 작용 | 입력 검증, 필터링, 출력 제한 |
Indirect Prompt Injection | 외부 컨텍스트 → 모델 | •공격자가 모델에 제공되는 문서, 컨텍스트, 외부 지식 등을 조작하여 간접적으로 모델 행동을 변경하는 경우
•직접 입력을 조작하지 않고, 모델이 참조하는 외부 컨텐츠나 메타데이터를 통해 공격 | 외부 자료 검증, 신뢰 제한, 안전 지침 강화 |
Prompt Injection과 함께 최근 두드러지는 위협이 [그림 1-5]와같이 오픈소스 기반 AI 공급망 공격이다. 오늘날 AI 모델 개발은 오픈소스 모델, 데이터셋, 라이브러리, 파이프라인 툴, 클라우드 인프라 등 다양한 외부 구성요소에 강하게 의존한다. 이러한 공급망 요소 중 단 하나라도 악성 코드가 포함되거나 의도적으로 변조된다면, 이를 이용해 개발·운영되는 AI 모델 역시 그대로 오염될 수 있다. 특히 공격자는 인기 오픈소스 플랫폼을 악용해 정상적으로 보이는 모델이나 패키지에 악성 페이로드를 삽입하고, 배포된 구성요소를 경유해 다양한 AI 시스템을 동시에 공격하는 사례가 실제로 증가하는 추세다.
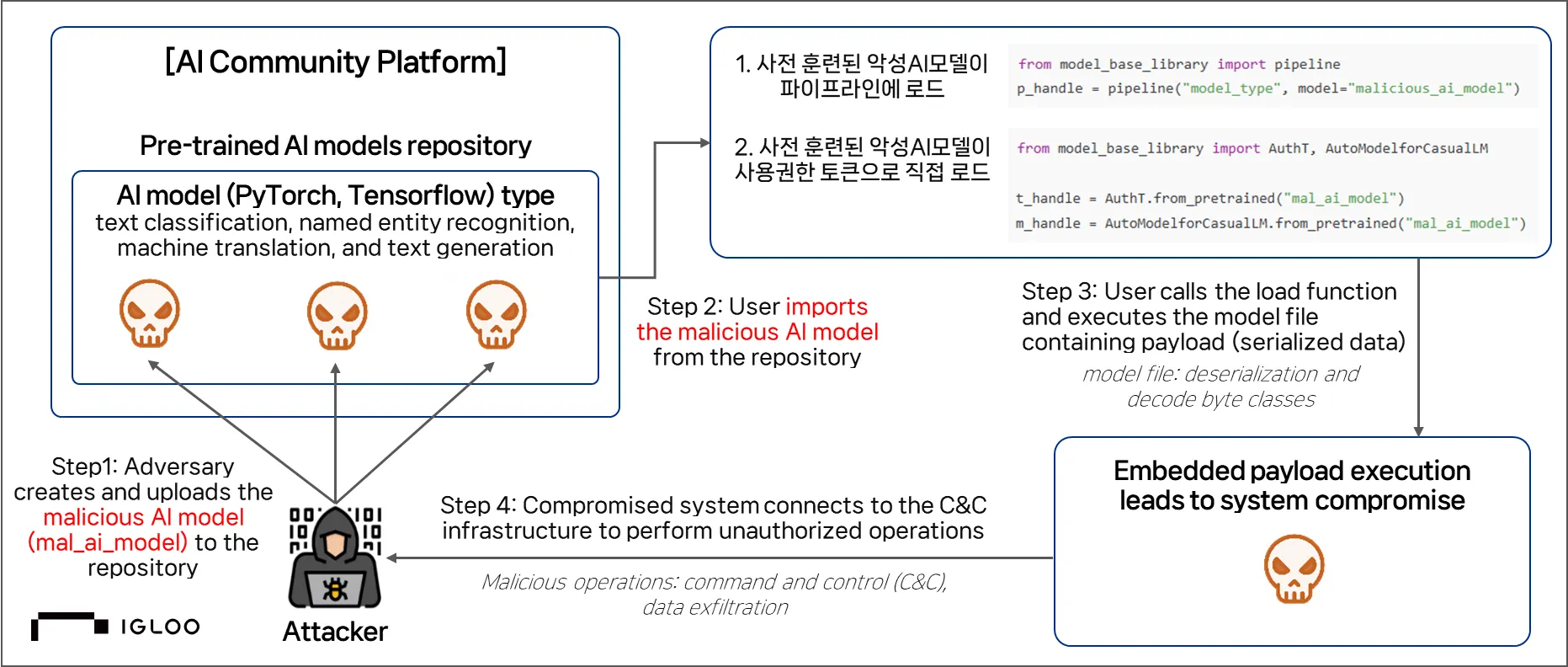
[표 1-4]와 같이 AI 공급망을 이용한 대표적인 공격 사례는 대표적인 사례는 Hugging Face와 같이 AI 모델 플랫폼을 이용한 악성코드 유포 방식이다. 공격자는 정상적인 텍스트 분류·NER·번역 등 범용 모델인 것처럼 위장한 악성 모델을 생성한 뒤, 이를 공개 저장소에 업로드한다. 사용자가 이를 로드하는 순간, 모델 내부에 직렬화된 악성 코드가 Python 환경에서 자동 실행되며 외부 C&C 서버와 연결되어 추가 명령을 수신하거나 시스템 정보 탈취, 임의 코드 실행 등 다양한 공격을 수행할 수 있었다.
Incident name | Year | Attack vector | Impact | Source |
Malicious models on Hugging Face | 2024 | Malicious payloads in model cards and metadata | Compromised developer environments via Hugging Face | |
Prompt injection attacks on LLMs | 2023–24 | Crafted user inputs override model behavior | Leaked prompts, API abuse, and misaligned outputs | |
AML.CS0028: AI Model Tampering via Supply Chain Attack | 2023 | Supply chain compromise | AI models poisoned by exploiting vulnerabilities in cloud-based container registries, leading to backdoored models being distributed through trusted channels | |
PyTorch dependency hijack (torchtriton) | 2022 | Typosquatting and dependency confusion in PyPI | System fingerprinting and data exfiltration |
AI 공급망은 기존 소프트웨어 공급망보다 훨씬 복잡하며, 모델·데이터·라이브러리·파이프라인·플랫폼 등 다양한 구성 요소가 맞물려 있다. 실제 사고 사례가 연이어 발생하면서 공격자들이 AI 생태계를 적극적으로 악용하고 있음을 확인할 수 있다. AI 개발이 가속화될수록 이러한 공격은 더욱 증가할 것이며, 조직은 이제 단순한 모델 품질 검증을 넘어 [표 1-5]를 반영한 AI 생명주기 전체에 대한 보안 검증 체계가 필요하다.
[그림 1-6] 악성AI모델 공격 흐름도(출처 : Malicious AI Models Undermine Software Supply-Chain Security, By Aditya K. Sood and Sherali Zeadally, Posted May 27 2025 일부 재구성)
[표 1-5] AI시스템 보안 위협 요소별 대응방안 (출처 : OWASP TOP 10 for LLM 2025)
OWASP Top 10 | 주요 예방 및 완화 전략 |
LLM01:Prompt Injection | •모델 행동 제약 : 시스템 프롬프트에서 모델 역할, 기능, 제한 사항 명시 및 핵심 지침 변경 시도 무시하도록 지시
•예상 출력 형식 정의 및 검증 : 명확한 출력 형식 지정, 상세한 추론 및 출처 인용 요청, 확정적 코드로 형식 준수 여부 검증
•입력 및 출력 필터링 : 민감한 카테고리 정의 및 처리 규칙 구성, 시맨틱 필터 및 문자열 검사 적용, RAG Triad(컨텍스트 관련성, 근거, 질문/답변 관련성)로 응답 평가
•최소 권한 원칙 적용 : LLM의 접근 권한을 필요한 최소한으로 제한 |
LLM02:Sensitive Information Disclosure | •데이터 무해화 : 학습 모델에 사용자 데이터가 제외되게 민감 내용 스크러빙 및 마스킹
•강력한 접근 통제 : 최소 권한 원칙에 따라 민감한 데이터 접근 제한
•차등 프라이버시활용 : 데이터나 출력에 노이즈를 추가하여 개별 데이터 역추적 방지
•시스템 서문(Preamble) 숨기기 : 시스템의 초기 설정 접근 및 재정의 능력 제한 |
LLM03:Supply Chain | •데이터 소스 및 공급업체 검토 : 개인정보 보호정책 및 신뢰된 공급업체만 사용
•OWASP Top Ten A06:2021 완화 방안 적용 : 취약점 스캐닝, 관리 및 패치
•AI 레드팀 및 평가 : 제3자 모델 선택 시 광범위한 AI 레드팀 활동을 통해 모델 평가
•SBOM 유지 : 구성 요소의 최신 재고 목록 유지 및 서명하여 변조 방지 |
LLM04: Data and Model Poisoning | •데이터 출처 및 변환 추적 : OWASP CycloneDX 또는 ML-BOM 같은 도구를 사용, 모든 모델 개발 단계에서 데이터 합법성 검증
•강력한 샌드박스 기술 적용 : 모델이 검증되지 않은 데이터 소스에 노출 제한
•데이터 버전 관리 사용 : 데이터 세트 변경 사항 추적 및 조작 감지
•RAG 및 Grounding 기술 통합 : 추론 단계에서 환각(hallucinations) 위험 감소 |
LLM05:Improper Output Handling | •제로 트러스트 접근 방식 채택 : 모델을 다른 사용자처럼 취급하고, 백엔드 기능으로 전달되는 모델 응답에 적절한 입력 유효성 검사 적용
•출력 인코딩 : 사용자에게 반환되는 모델 출력에 인코딩을 적용해 원치 않는 코드 실행 완화 (HTML, JavaScript, SQL 등 사용처에 따른 컨텍스트 인식 인코딩)
•매개변수화된 쿼리 사용: LLM 출력이 포함된 모든 데이터베이스 작업에 대해 적용 |
LLM06:Excessive Agency | •확장 기능 최소화 : LLM 에이전트가 호출할 수 있는 확장 기능을 최소한으로 제한
•개방형 확장 기능 사용 회피 : 가능한 한 구체적 기능의 확장 기능 사용
•사용자 승인 요구 : 영향도가 높은 작업은 'Human-in-the-loop' 통제 장치 활용 |
LLM07:System Prompt Leakage | •민감한 데이터를 시스템 프롬프트에서 분리 : API 키, 인증 키, 데이터베이스 이름 등 민감 정보는 모델이 직접 접근하지 않는 시스템으로 외부화
•행동 제어를 위한 시스템 프롬프트 의존 회피 : 프롬프트 주입 등에 취약하므로, 외부 시스템에 의존하여 모델 행동 보장
•가드레일 구현 : LLM 외부에 독립적인 가드레일 시스템 구현 후 출력과 예상치 검사 |
LLM08:Vector and Embedding Weaknesses | •권한 및 접근 제어 : 세분화된 접근 제어 및 권한 인식 벡터/임베딩 저장소 구현. 벡터 데이터베이스 내 데이터 세트의 엄격한 논리적/접근 분할 보장
•데이터 유효성 및 출처 인증 : 지식 출처에 대한 강력한 유효성 검사 파이프라인 구현
•모니터링 및 로깅 : 검색 활동 중 의심스러운 행동에 신속하게 대응 |
LLM09:Misinformation | •RAG 사용 : 신뢰 가능한 외부 데이터베이스 검증 정보 검색해 모델 출력 신뢰성 향상
•상호 검증 및 인간 감독 : 사용자에게 LLM 출력 신뢰가능한 외부 출처 교차 확인 권장
•자동 유효성 검사 메커니즘: 주요 출력 자동 유효성 검사 도구 및 프로세스 구현
•위험 커뮤니케이션 : LLM 생성 콘텐츠의 위험과 한계를 사용자에게 명확하게 전달 |
LLM10:Unbounded Consumption | •입력 유효성 검사 : 입력이 합리적인 크기내에 엄격한 입력 유효성 검사 구현
•Rate Limiting 및 사용자 할당량 : 단일 출처 엔티티 특정기간 내 수행할 요청 수 제한
•타임아웃 및 스로틀링 : 리소스 집약적 작업에 대한 타임아웃 설정 및 처리량 제한
•로깅, 모니터링 및 이상 감지 : 리소스 사용량 지속적 모니터링 및 이상 패턴 감지 |
IGLOO Corp. 2025. All rights reserved.